Специальные виды свёрток
Поточечная свёртка
Поточечная свёртка (pointwise convolution [1]) - это обычная свёртка, но с размером ядра , где - число входных каналов. Таким образом, в каждой точке поточечная свёртка генерирует признак, который зависит лишь от входных признаков в той же самой пространственной позиции.
Таким образом, выходной слой поточечной свёртки представляет собой линейную комбинацию входных слоёв.
Применяя набор поточечных свёрток, можно управлять числом выходных каналов, то есть размерностью внутреннего представления изображения. Это полезно для того, чтобы понизить размерность каналов, сократив тем самым объём вычислений перед применением обычных свёрток большого размера, поскольку их сложность линейно зависит от числа каналов.
Групповая свёртка
Групповая свёртка (grouped convolution [2]) призвана уменьшить как число вычислений, так и число настраиваемых параметров за счёт того, что набор свёрток применяется не ко всем входным каналам, а только к части (каждый блок свёрток применяется к своему подмножеству входных каналов).
Рассмотрим для примера свёрточный слой с двумя равными группами.
Стандартная свёртка зависит от всех каналов, что даёт сложность для вычисления одной активации свёртки с ядром . В групповой свёртке с двумя группами каналы �разбиваются на две половины. Используя нотацию питона для индексирования массивов, можно записать, что к первой половине каналов применяется свёртка с ядром , а ко второй группе каналов применяется свёртка с ядром , при этом смещение у двух уполовиненных свёрток разное. Активациии первой и второй свёртки затем конкатенируются вдоль размерности каналов (channel dimension).
Область значений, от которых зависят стандартная свёртка и групповая с двумя группами, показаны ниже слева и справа соответственно:
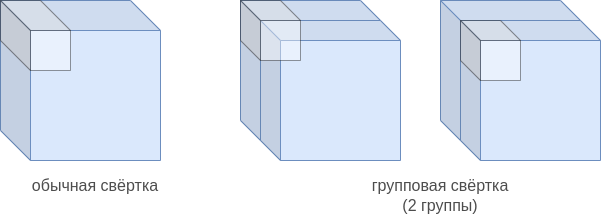
В общем случае используется групп: входные каналы разбиваются на непересекающиеся группы примерно одинакового размера, а результаты действия свертки в каждой группе затем конкатенируются вдоль размерности выходных каналов.
Таким образом, расчёт свёрточного слоя групповых свёрток с группами будет
Выходом будет конкатенация всех выходов вдоль размерности каналов:
В примере число входных и выходных каналов совпадает. Но так делать необязательно. Например, если к каждой группе применять в два раза меньшее число свёрток, чем число каналов в группе, то и итоговое выходное число каналов будет в два раза меньше.
Параметрами слоя будут ядра и смещения для каждого выходного канала в рамках каждой группы.
Таким образом, групповая свёртка эквивалентна разбиению входа вдоль каналов на K групп, применению независимых свёрток к каждой группе, а потом объединению полученных результатов вдоль размерности выходных каналов.
Групповая свёртка сокращает число вычислений и параметров примерно в S раз ценой извлечения менее выразительных признаков, поскольку признаки теперь зависят не от всех входных каналов, а лишь от каналов группы.
Поканальная свёртка
Поканальная свёртка (depthwise convolution [3]) - это частный случай групповой свёртки, когда число групп совпадает с числом входных каналов, то есть на каждый канал выделяется своя группа. Получается, что каждый канал обрабатывается независимо свёрткой с плоским ядром и смещением . Число применяемых свёрток при этом совпадает с числом входных каналов .
Объём вычислений сокращается максимально - в раз, где - число каналов, но каждый выходной признак будет зависеть только от одного своего канала.
Чтобы выходные каналы зависели не только от соответствующих входных каналов, а сразу от всех, после применения поканальной свёртки рекомендуется применить поточечную свёртку. Такая комбинация двух свёрток называется поканальной сепарабельной свёрткой (depthwise separable convolution [3]) и представляет собой частый приём при создании вычислительно эффективных свёрточных архитектур.
Сложность (в терминах операции умножения) однократного применения обычной свёртки из в каналов будет , а у поканальной сепарабельной будет лишь .
Будет ли поканальная сепарабельная свёртка эквивалентна обычной свёртке? Почему?
Визуализацию работы представленных видов свёрток можно посмотреть в [4].
Динамическая свёртка
Параметры свёртки в свёрточных слоях можно изменять в зависимости от задачи. Для этого применяется динамическая свёртка (dynamic filter [5]), веса которой предсказываются другой нейросетью (filter generating network).
Схематично процесс генерации параметров свёртки показан на рисунке ниже, когда параметры свёртки постоянны (а), и когда они меняются в зависимости от позиции, к которой применяется свёртка (b) [7]:

По сути, это частный случай гиперсети (hypernetwork), когда предсказываются веса свёрточных слоёв.
Рассмотрим в качестве примера задачу стилизации изображений (neural style transfer [6]), в которой требуется перерисовать фотографию в стиле картины известного художника. Эту задачу можно решить, преобразуя входную фотографию набором свёрточных слоёв. Но как обеспечить применимость архитектуры к разным стилевым изображениям?
Можно подставлять в середине архитектуры различные свёртки в зависимости от того, какой именно стиль мы хотим воспроизвести, как сделано в [7]. Тем самым, одна и та же нейросеть будет способна генерировать различные стили, нужно лишь изменить одно преобразование в её середине.
Но этот подход будет требовать обучения своего фильтра для каждого нового стиля. Вместо этого подхода можно воспользоваться отдельной сетью, которая по изображению стиля будет сразу генерировать параметры подходящего свёрточного слоя, как предложено в [8]. Тогда не потребуется донастройка свёрточного слоя, если пользователю понадобится осуществить стилизацию новым стилем (zero shot learning)!
Литература
- Lin M., Chen Q., Yan S. Network in network //arXiv preprint arXiv:1312.4400. – 2013.
- Krizhevsky A., Sutskever I., Hinton G. E. Imagenet classification with deep convolutional neural networks //Advances in neural information processing systems. – 2012. – Т. 25.
- Chollet F. Xception: Deep learning with depthwise separable convolutions //Proceedings of the IEEE conference on computer vision and pattern recognition. – 2017. – С. 1251-1258.
- youtube.com: Groups, Depthwise, and Depthwise-Separable Convolution.
- Jia X. et al. Dynamic filter networks //Advances in neural information processing systems. – 2016. – Т. 29.
- Jing Y. et al. Neural style transfer: A review //IEEE transactions on visualization and computer graphics. – 2019. – Т. 26. – №. 11. – С. 3365-3385.
- Chen D. et al. Stylebank: An explicit representation for neural image style transfer //Proceedings of the IEEE conference on computer vision and pattern recognition. – 2017. – С. 1897-1906.
- Shen F., Yan S., Zeng G. Neural style transfer via meta networks //Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. – 2018. – С. 8061-8069.