Интерпретация прогнозов
Выделение регионов, отвечающих за класс
Актуальной задачей для интерпретации работы свёрточной сети, классифицирующей изображения, является выделение регионов на изображении, голосующих за тот или иной класс.
Такой анализ полезно проводить в процессе отладки модели, чтобы убедиться, что она корректно работает: объекту каждого класса должен соответствовать действительно тот регион изображения, на которых он представлен. Также этот анализ позволяет объяснить неожиданные контринтуитивные прогнозы модели, показывая части изображения, свидетельствующие в пользу выбранного прогноза.
Для работы метода нужно выбрать изображение (трёхмерный тензор интенсивностей каждого цвета) и интересуемый класс , после чего работать с его вероятностью или ненормированным рейтингом класса до SoftMax -преобразования.
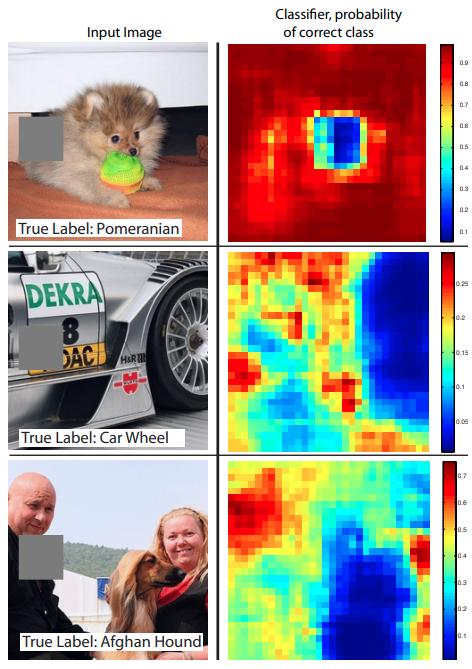
Анализ закрасок
В анализе закрасок (occlusion analysis) [1] на классифицируемом изображении последовательно закрашиваются небольшие квадратные участки, после чего визуализируется карта предсказанной вероятности интересуемого класса для модифицированного изображения. Каждой позиции на этой карте соответствует вероятность , где - изображение, на котором затёрта квадратная часть серым цветом с центром в позиции . Примеры таких карт для верного класса (указанного внизу соответствующих изображений) показаны ниже [1]:
Градиент по изображению
В работе [2] предлагается другой способ локализации регионов, отвечающих за тот или иной класс. Для этого строится пространственная карта градиентов (gradient map) по рейтингу интересующего класса на входном изображении:
Данная карта вычисляется однократным проходом назад (backward pass) в методе обратного распространения ошибки. Градиент вычисляется не по весам модели, а по пикселям изображения, поэ�тому карта градиентов будет иметь тот же размер, как и исходное изображение.
Далее карта градиентов преобразуется в карту выраженности (saliency map) , где и - высота и ширина рассматриваемого изображения.
В случае чёрно-белого изображения размера выраженность считается как модуль градиента
а в случае цветного - как максимальный градиент вдоль цветовых каналов R,G,B:
Ниже приведены примеры карт выраженности для нескольких изображений относительно предсказанного класса [2]:

Как видим, предсказанный класс локализован верно, хоть и с сильным шумом. В последующих работах были предложены различные улучшения (Guided Backpropagation [4] и Deconvolution [1]), позволяющие получить выделение класса более чётко.
Градиент по слою
Одним из способов избежать шумных оценок по отдельным пикселям является выявление связи не между рейтингом класса и исходными пикселями, а между рейтингом класса и картой активаций последнего свёрточного слоя, что было реализовано в методе Grad-CAM [3].

Пусть - рейтинг интересующего класса (перед SoftMax), а - значение карты активаций (feature map) -го канала последнего свёрточного слоя сети в позиции . Сама карта представляет собой матрицу .
Вначале вычисляются важности каждой карты глобальным усредняющим пулингом:
Тогда карта выраженности для класса считается по правилу:
Нелинейность ReLU применяется, чтобы выделить только те области, которые положительно влияют на класс (что, в частности, реализуется, и когда активации сильно отрицательные, но и градиент по ним отрицательный).
Полученная карта важности будет иметь размер последнего свёрточного слоя , поэтому её нужно увеличить до размера исходного изображения перед тем, как на него наложить.
Характерные изображения класса
Рассмотрим свёрточную нейросеть для классификации изображений. Такая нейросеть выдаёт рейтингов классов , которые впоследствии проходят через SoftMax-преобразование, чтобы вычислить вероятности классов.
В работе [1] предложен способ визуализации того, как нейросеть представляет тот или иной класс. Допустим, нас интересует класс . Для определения того, как нейросеть его видит, решается следующая оптимизационная задача:
то есть находится такое характерное изображение , которое бы максимизировало рейтинг соответствующего класса. Чтобы избежать бесконтрольного изменения интенсивностей пикселей, изображение дополнительно регуляризуется по L2-норме (второе слагаемое в критерии оптимизации).
Максимизируется именно рейтинг класса, а не его вероятность, поскольку максимизация вероятности могла бы вырождаться в то, чтобы уменьшать вероятности других классов, а не концентрироваться вероятности целевого класса. Именно такой способ обеспечивал более выразительные результаты визуализации.
Примеры изображений, визуализирующих различные классы датасета ILSVRC-2013 на модели AlexNet, приведены ниже [2]:

Другие подходы к визуализации
Для интерпретации отдельных свёрточных фильтров можно перебирать на изображениях различные фрагменты, от которых зависит соответствующая свёртка (receptive field) и визуализировать те фрагменты, которые приводят к максимальной активации выбранной свёртки. Примеры такой визуализации отдельных свёрток на всё более глубоких слоях свёрточной сети приведены ниже [1]:

Как видим, более глубокие слои захватывают всё более обширную область изображения и выделяют семантически более сложные признаки, что согласуется с ранее описанными свойств�ами суперпозиции свёрток.
Обратим внимание, что на первом слое можно визуализировать свёрточные фильтры непосредственно, поскольку их ядра имеют размер , поэтому сами ядра могут интерпретироваться как изображения. Свёртки максимально активируются, когда обрабатываемые фрагменты будут наиболее похожи на их ядра. Последующие свёртки не допускают подобной непосредственной визуализации, поскольку будут обрабатывать уже больше трёх слоёв.
Также можно визуализировать изображения, приводящие к получаемым активациям заданных свёрток внутри свёрточной сети.
Для этого фиксируется слой, на котором располагается интересующий свёрточный фильтр. Далее обучается декодировщик (deconv net [1]), восстанавливающий исходные изображения по внутреннему представлению изображений на выбранном слое.
Для интерпретации интересующей свёртки все активации выбранного слоя зануляются, кроме активаций канала анализируемой свёртки, и полученное внутреннее представление пропускается через обученный декодировщик для получения итоговой визуализации.