Нормализация свёрточных слоёв
Для повышения устойчивости и скорости настройки свёрточной нейросети применяется нормализация свёрточных слоёв (convolutional layer normalization).
Эта нормализация несколько отличается от батч-нормализации и нормализации слоя в многослойном персептроне, учитывая специфику обработки пространственных данных на изображениях.
Особенностью свёрточного слоя является то, что свёртка извлекает один и тот же признак в разных локациях на изображении. Таким образом, применив свёртку, мы получаем карту пространственной размерности значений одного и того же признака, где - высота, а - ширина карты признаков. Применив свёрток, мы получим реализаций каждого из признаков, извлекаемых каждой свёрткой.
Настройка параметров нейросети производится мини-батчами из изображений.
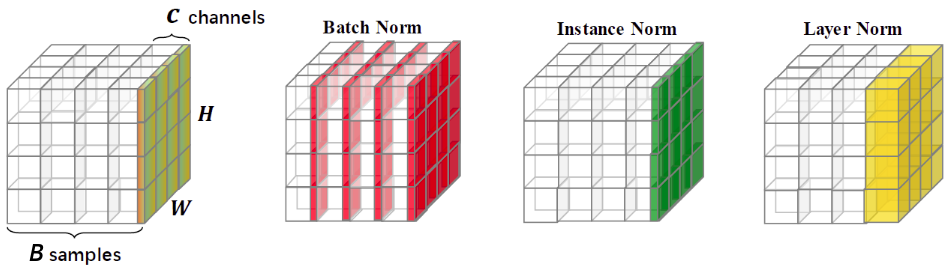
Таким образом, внутреннее представление изображений мини-батча можно представить в виде тензора размера , как показано на рисунке слева, а основные виды нормализации свёрточных слоёв (batch norm, instance norm, layer norm) - справа [1]:
Каждый тип нормализации задаётся одной и той же формулой, перевзвешивающей активации каналов :
где - активация -й свёртки в позиции для изображения в мини-батче. - малый параметр, чтобы избежать деления на ноль, а - настраиваемые параметры.
Виды нормализации свёрточных слоёв
Батч-нормализация (batch-normalization [2]) усредняет активации по различным изображениям мини-батча и по различным позициям на каждом изображении:
Расчет меняется в режимах обучения и применения сети точно так же, как и в обычной батч-нормализации.
Нормализация экземпляра (instance normalization [3]) усредняет независимо для каждого изображения только по его реализациям на различных позициях на изображении:
Расчет не меняется в режимах обучения и применения сети.
Нормализация слоя (layer normalization [4]) усредняет независимо для каждого изображения по всевозможным признакам на всевозможных позициях на изображении:
Расчет не меняется в режимах обучения и применения сети.
Литература
- Neupane D., Kim Y., Seok J. Bearing fault detection using scalogram and switchable normalization-based CNN (SN-CNN) //IEEE Access. – 2021. – Т. 9. – С. 88151-88166.
- Ioffe S., Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift //International conference on machine learning. – pmlr, 2015. – С. 448-456.
- Ulyanov D., Vedaldi A., Lempitsky V. Instance normalization: The missing ingredient for fast stylization //arXiv preprint arXiv:1607.08022. – 2016.
- Ba J. L., Kiros J. R., Hinton G. E. Layer normalization //arXiv preprint arXiv:1607.06450. – 2016.