Гиперсеть
Обычно нейросети используются, чтобы предсказывать значение, отвечающее какой-либо характеристике реального мира. Однако можно настроить нейросеть, называемую гиперсетью (hypernetwork, [1]), таким образом, чтобы она предсказывала веса другой целевой нейросети (target network).
Первый и второй подходы показаны на левой и правой стороне схемы [1]:
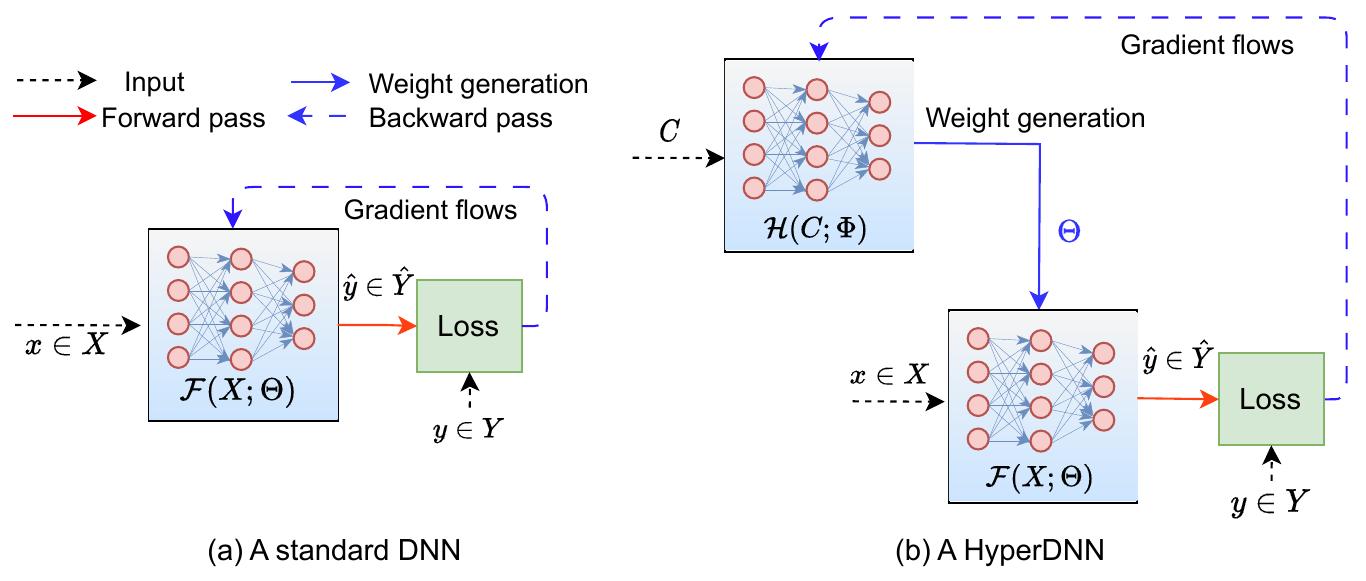
Во время обучения настраиваются не веса целевой сети, генерирующей итоговые прогнозы, а веса гиперсети, потому что именно гиперсеть генерирует веса основной сети и ответственна за её ошибки.
Использование гиперсети даёт следующие преимущества:
-
Если на вход гиперсети подавать объект для прогноза, то она может подстроить основную сеть таким образом, чтобы она лучше всего обработала именно такой объект. Например, при распознавании лиц человек может быть сфотографирован в фас или в профиль. Соответственно, гиперсеть оценит положение головы и сгенерирует обработчик именно для нужного ракурса.
-
Основная сеть, генерируемая гиперсетью, может содержать разное число слоёв. Это даёт возможность обрабатывать простые объекты более короткой сетью, чем более сложные. Таким образом, гиперсеть позволяет более эффективно распоряжаться вычислительными ресурсами.
-
Если решается несколько похожих по смыслу задач, например, детекция машин, грузовиков и мотоциклов, то вместо того, чтобы настраивать под каждый вид транспортного средства свою сеть, можно настроить гиперсеть, которой дополнительно будем передавать тип задачи (что именно хотим распознать). Получим более экономичную архитектуру (всего одна сеть), которая, скорее всего, окажется и более точной, поскольку будет настраиваться по данным не одной отдельно взятой задачи, а по всем сразу. Поскольку задачи семантически связаны, то они будут переиспользовать схожие признаки, которые и сгенерирует гиперсеть. По сути, гиперсеть реализует принцип мягкой общности весов (soft weight sharing), связывая параметры различных моделей общей сетью-генератором.
-
Если целевая сеть содержит много слоёв, то хранить все параметры для них может быть очень расточительным, особенно на слабых вычислителях, таких как мобильный телефон. Поэтому эффективнее хранить более компактную гиперсеть, которая будет генерировать веса для большой целевой сети только тогда, когда это необходимо. По сути, гиперсеть реализует алгоритм сжатия весов (weights compression).
-
Гиперсеть можно настроить таким образом, чтобы она выдавала рандомизированный выход, т.е. выход с элементами случайности. Этого можно добиться, если добавлять случайный шум к промежуточному слою гиперсети. Перезапуская гиперсеть несколько раз, будем получать различные основные сети, решающие одну и ту же задачу. С помощью этого набора сетей мы сможем сгенерировать набор прогнозов, в результате чего сможем оценить не только значение окончательного прогноза (среднее от всех прогнозов), но и неопределённость прогноза (стандартное отклонение прогнозов). Это важно, чтобы понимать, насколько прогнозу можно доверять, исходя из того, согласуются ли прогнозы отдельных целевых сетей между собой.