В качестве базовых алгоритмов f1(x),...fM(x) можно брать любые алгоритмы, способные обучаться на взвешенной обучающей выборке (где каждое наблюдение учитывается со своим весом).
Обучение на взвешенной выборке
Большинство алгоритмов машинного обучения допускает минимизацию средних потерь на взвешенной выборке. Например, в решающих деревьях необходимо каждый объект (xn,yn) учитывать wn раз при расчете функции неопределённости и минимизации потерь в листе.
Если алгоритм настройки не позволяет учитывать веса, можно сгенерировать обучающую выборку, в которой каждый объект будет повторяться пропорционально его весу (например, если вес равен 3, то объект в выборке ну�жно повторить 3 раза). Но этот способ работает только для целочисленных весов (таких как 1,2,3,...) и может приводить к большому разрастанию выборки.
Альтернативно (хоть это и не то же самое, а лишь приближение) можно обучать модель на случайной подвыборке объектов, в которую каждый объект попадает из обучающей выборки с вероятностью, пропорциональной весу наблюдения wn.
Результатом работы AdaBoost является относительный рейтинг положительного класса
GM(x)=c1f1(x)+c2f2(x)+...+cMfM(x),
а прогноз осуществляется знаком величины GM(x):
y(x)=sign(GM(x))=sign(m=1∑Mcmfm(x))
Алгоритм AdaBoost
Инициализируем веса объектов wn0=1/N,n=1,2,...N.
Для каждого m=1,2,...M:
Настраиваем fm(x) по выборке {(xn,yn)}n=1N с весами {wn}n=1N.
Вычисляем взвешенную частоту ошибок:
Em=∑n=1Nwn∑n=1NwnI[fm(xn)=yn]
Если Em=0 или Em≥0.5, то останавливаем построение ансамбля.
Проверка Em=0 на шаге 3 производится, поскольку если Em=0, то fm(x) безошибочно классифицирует все объекты выборки, и можно использовать только эту модель для классификации. На практике такое реализуется редко, поскольку в качестве базовых моделей используются очень простые алгоритмы, такие как деревья решений небольшой глубины.
Как видно по шагу алгоритма 2.i, каждая базовая модель fm(x) настраивается на одну и ту же исходную обучающую выборку {(xn,yn)}n=1N, меняются лишь веса, с которыми учитывается каждый объект.
Нормировка на шаге 2.vi производится для численной устойчивости, иначе веса могут снижаться до машинного нуля либо возрастать слишком сильно.
Из шага 2.v, видно, что веса зависят от промежуточного ансамбля Gm(x) следующим образом:
Знак ∝ означает "равен с точностью до константы", которая возникает в силу того, что веса перенормируются на шаге 2.vi, чтобы суммироваться в единицу.
Этот вид весов очень интуитивен, поскольку ynGm(x) представляет собой отступ при классификации объекта x ансамблем Gm(x) и по смыслу представляет собой качество классификации этого объекта. Чем качество классификации объекта выше, тем соответствующий вес ниже, и следующая базовая модель будет слабее его учитывать. А чем качество ниже, тем вес проблемного объекта выше, что вынуждает следующую базовую модель сильнее его учитывать, чтобы исправить неточную классификацию.
Обобщение подхода
По аналогии с AdaBoost можно разработать собственную версию итеративного построения ансамбля, где на каждом шаге настраивается одна и та же модель по одной и той же обучающей выборке, но вес проблемных объектов повышается, а хорошо предсказанных - снижается по пользовательскому правилу.
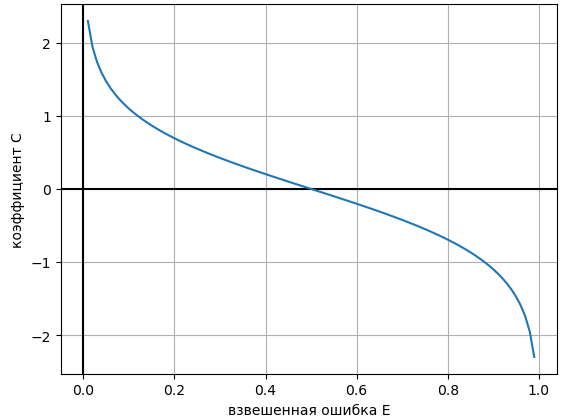
На шаге 2.4 рассчитывается коэффициент при следующей базовой модели. Его зависимость от взвешенной частоты ошибок имеет вид:
Отсюда видно, что вес, с которым добавляется следующая базовая модель fm(x), тем выше, чем точнее она работает (Em ниже). Если Em=0.5, то cm=0 и новая базовая модель добавится с нулевым весом, не изменив ансамбль. Веса на шаге 2.v также не изменятся, поэтому последующие запуски алгоритма ничего изменять не будут. В связи с этим, при Em=0.5 на шаге 2.iii целесообразно досрочно останавливать алгоритм. При очень плохом классификаторе с частотой ошибок Em>0.5 процесс также останавливается, хотя остаётся вариант инвертировать его прогнозы (сделав Em<0.5) и продолжить процесс обучения.
Условие Em<0.5 гарантирует, что всегда выполнено условие cm>0.
Функция потерь, как сумма выпуклых функций (экспонент с неотрицательными коэффициентами), является выпуклой по cm. Поэтому не только необходимым, но и достаточным условием минимума является равенство нулю производной потерь в формуле (2):
Первое слагаемое от fm(x) не зависит. Во втором слагаемом, поскольку cm>0, то ecm−e−cm>0, следовательно, для минимизации потерь по fm(x) необходимо, чтобы fm(x) решала задачу минимизации взвешенного числа ошибок: