Сравнение бустинга с другими ансамблями моделей
Бустинг и бэггинг
Ранее изученные алгоритмы построения ансамбля, такие как бэггинг, метод случайных подпространств и случайный лес, настраивают модели независимо друг от друга, что снижает переобученность базовых моделей (снижает дисперсию их ошибок в разложении на смещение и разброс). Это позволяет эффективно распределить настройку каждой модели по разным вычислительным устройствам. Также нельзя переобучиться по числу базовых моделей - при увеличении их числа среднее качество ансамбля будет только расти. Однако независимость построения каждой базовой модели не позволяет моделям исправлять систематические ошибки ансамбля.
В бустинге же модели настраиваются последовательно, исправляя ошибки уже настроенного ансамбля. В результате этого происходит борьба с недообученностью базовых моделей (снижение систематического смещения базовых моделей в разложении на смещение и разброс). Поэтому алгоритм бустинга, как правило, работает точнее бэггинга, но требует более тщательной настройки по числу базовых моделей, поскольку может переобучаться, если их выбрать слишком много, как показано на графике:
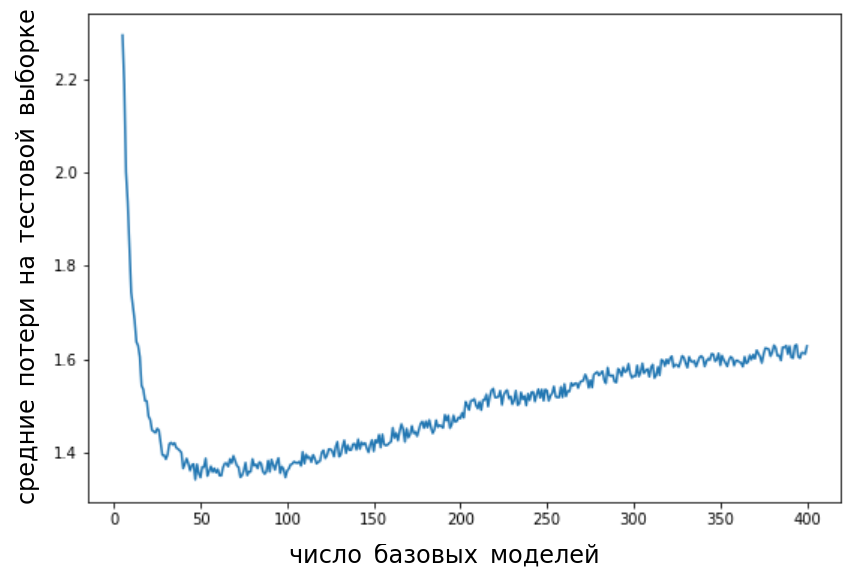
Для подбора оптимального количества базовых моделей нужно отслеживать качество ансамбля на отдельной валидационной выборке.
Также итеративная процедура настройки базовых моделей в бустинге не допускает параллелизацию в их обучении: настроить следующую модель возможно, лишь когда настроены все предыдущие!
Бустинг и стэкинг
Итеративная процедура настройки модели и коэффициента при ней в бустинге позволяет быстро строить линейную агрегирующую модель (как в линейном стэкинге), однако коэффициент при текущей модели учитывают ошибки только предшествующих моделей, но не будущих. Также базовые модели в стэкинге настраиваются предсказывать конечную целевую переменную, а в бустинге - ошибку прогнозирования текущим ансамблем.