Улучшения градиентного бустинга
Есть две популярные техники, призванные улучшить качество итоговой модели градиентного бустинга - сжатие и сэмплирование.
Сжатие
В традиционном градиентном бустинге обновление ансамбля происходит добавлением новой базовой модели с коэффициентом (если модель - решающее дерево, то без коэффициента):
Идея сжатия (shrinkage) основана на том, чтобы добавлять не полностью, а с некоторым малым коэффициентом :
В случае обновления ансамбля с фиксированным шагом
домножать отдельно на смысла нет, так как достаточно просто уменьшить множитель .
Чем базовых моделей в ансамбле больше, тем весь ансамбль в среднем получается точнее, поскольку модели отчасти компенсируют ошибки друг друга. Сжатие позволяет искусственно увеличить число базовых моделей в ансамбле, снижая вклад каждой базовой модели в отдельности. Чем гиперпараметр меньше, тем больше шагов потребуется произвести, чтобы дойти до оптимального решения, поскольку двигаться мы будем более малыми шагами. Вместе они связаны следующим соотношением:
Например, если двигаться с уменьшенным шагом в десять раз, то потребуется в 10 раз больше итераций.
Такая модификация улучшает качество прогнозов за счёт того, что алгоритм точнее сойдётся к оптимуму. Обычно выбирают .
Цена повышения точности - увеличение вычислительных ресурсов, поскольку придётся дольше обучать ансамбль, а также производить больше вычислений, чтобы строить каждый прогноз увеличенным числом базовых моделей.
Рассмотрим задачу классификации. Пример зависимости точности градиентного бустинга от числа базовых моделей д�ля различных значений приведён ниже:
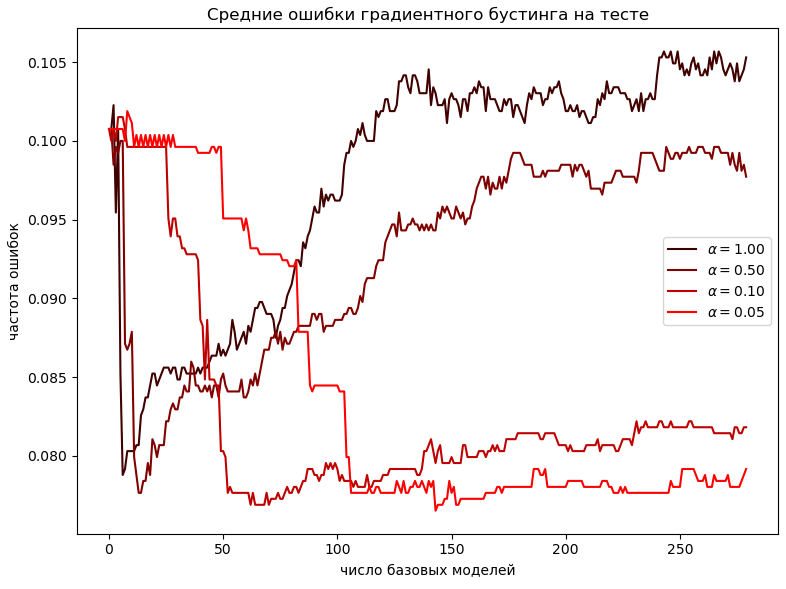
Как видим, уменьшение приводит к более высокому числу базовых моделей в оптимальной конфигурации. Зато точность ансамбля повышается!
Чтобы найти наилучшую конфигурацию бустинга быстрее, поступают следующим образом:
-
С большим по сетке значений настраивают параметры градиентного бустинга. Это включает оптимальное число базовых моделей , глубину решающих деревьев, критерий неопределённости при их настройке и прочие гиперпараметры.
-
Уменьшают в раз:
-
Увеличивают оптимальное число базовых моделей в раз:
В итоге получаем готовую модель, настройка гиперпараметров которой производилась быстрее по её вычислительно эффективной аппроксимации!
Сэмплирование
В обычной реализации бустинга каждая базовая модель настраивается, используя все объекты и признаки обучающей выборки.
Идея сэмплирования (subsampling) заключается в том, чтобы настраивать каждую базовую модель, используя случайную подвыборку из объектов и признаков, сэмплируемых без возвращения. В результате:
-
настройка бустинга производится быстрее;
-
базовые модели становятся более разнообразными, что повышает итоговую точность ансамбля исходя из разложения неоднозначности.
Поскольку для каждой базовой модели подмножество используемых объектов и признаков своё, а ансамбль состоит из большого числа таких моделей, то итоговая модель будет зависеть почти от всех объектов и признаков.
Настройка базовых моделей бустинга по подмножеству объектов также позволяет использовать out-of-bag оценку для оценки качества ансамбля, не прибегая к дополнительной валидационной выборке.
При использовании сэмплирования возникают гиперпараметры:
-
доля сэмплируемых объектов;
-
доля сэмплируемых признаков.
Для оптимальной точности метода их необходимо настроить, используя отдельную валидационную выборку или кросс-валидацию.
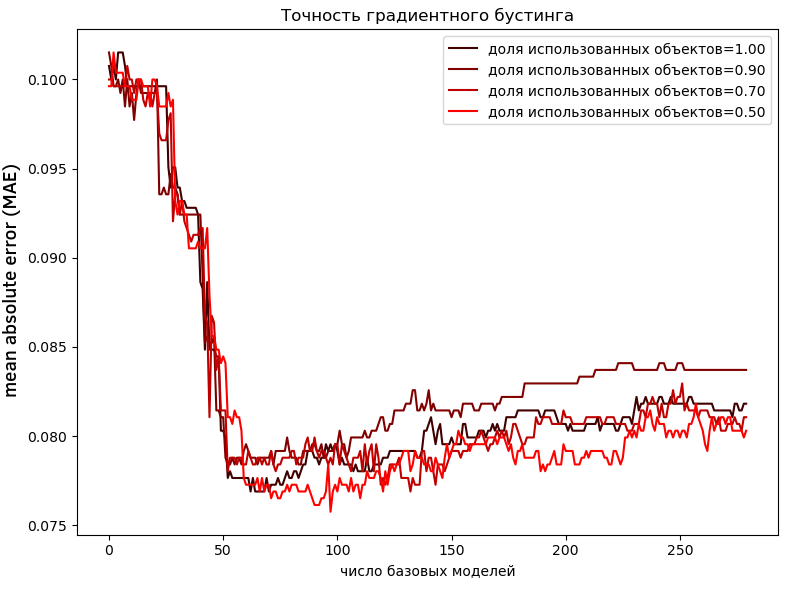
Рассмотрим задачу регрессии. Пример зависимости средней ошибки MAE на тестовой выборке от доли использованных объектов приведён ниже:
Далее приведён пример зависим�ости от числа сэмплируемых признаков:
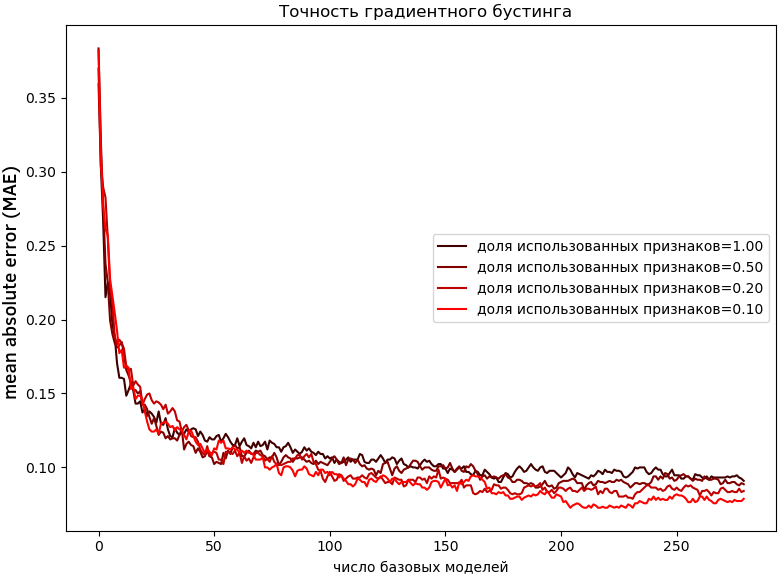
В приведённых примерах настройка базовых моделей не на всех, а на случайной части объектов и признаков привела к улучшению точности ансамбля.
В отличие от , которое чем меньше, тем лучше при достаточном числе базовых моделей, зависимость от доли используемых объектов и признаков сложна и неоднозначна и требует тщательного подбора по валидационной выборке или кросс-валидации.
Ид�ея использования не всех объектов, а случайной подвыборки при настройке базовых моделей была предложена в [1]. Механизмы shrinkage и subsampling также описаны в [2].
Поиск разбиений по сетке
При использовании решающих деревьев в качестве базовых моделей бустинга вместо того, чтобы перебирать все допустимые пороги, можно перебирать пороги только по грубой сетке значений. Для этого рекомендуется использовать 10,20,30, ... 90% квантильные значения признака для объектов, попадающих в соответствующий узел дерева. Можно использовать и другую сетку квантизации. Это ускоряет выбор правил при настройке решающих деревьев, снижая точность подгонки под данные. Но высокая точность в бустинге нам и не нужна, поскольку неточности в настройке текущей базовой модели исправят последующие модели ансамбля.
Подобная квантизация порогов используется, например, в алгоритме xgBoost [3].