Градиентный бустинг
Градиентный бустинг (gradient boosting [1], предложен в [2]) представляет собой приближение бустинга с использованием градиента функции потерь. В отличие от AdaBoost, он работает с произвольной дифференцируемой функцией потерь, а не только с экспоненциальной. В частности это позволяет решать не только задачу классификации, но и регрессии.
В качестве базовых моделей чаще всего используются решающие деревья небольшой глубины (gradient boosting over decision trees, GBDT).
Когда говорят о бустинге, то чаще всего имеют ввиду именно градиентный бустинг.
Идея метода
Если отвлечься от множителя при базовой функции, то в бустинге решается задача подбора оптимальной fm+1(x) такой, чт�о
L(fm)=N1n=1∑NL(Gm(xn)+fm(xn),yn)→fmmin
Если вектор прогнозов функции [fm(x1),fm(x2),...fm(xN)] заменить на вектор вещественных чисел u=[u1,u2,...uN], то задача переформулируется в виде классической минимизации функции по аргументам:
L(u)=L(u1,...uN)=N1n=1∑NL(Gm(xn)+un,yn)→u1,u2,...uNmin
Используя идеологию градиентного спуска, эту задачу в линейном приближении можно решить, положив
u1u2uN=−∂G∂L(Gm(x1),y1)=−∂G∂L(Gm(x2),y2)⋯=−∂G∂L(Gm(xN),yN)
Следовательно, в исходной постановке следует выбирать fm(x) так, чтобы обеспечить
fm(x1)fm(x2)fm(xN)≈−∂G∂L(Gm(x1),y1)≈−∂G∂L(Gm(x2),y2)⋯≈−∂G∂L(Gm(xN),yN)
На практике это означает обучение fm(x) на обучающей выборке:
{(x1,−∂G∂L(Gm(x1),y1)),(x2,−∂G∂L(Gm(x2),y2)),...(xN,−∂G∂L(Gm(xN),yN))}Алгоритм градиентного бустинга основан на итеративной оценке fm(x) для m=1,2,...M и добавлении этих функций к ансамблю Gm(x).
Заметим, что в обучающей выборке для каждой базовой модели fm вектора признаков будут одинаковыми, а целевые значения - разными, поскольку разными будут ошибки Gm(x), уточняемой на каждой итерации.
Настройка fm(x) происходит по правилу:
n=1∑N(fm(xn)+∂G∂L(Gm−1(xn),yn))2→fmmin
Заставить fm(x) приближать антиградиент а�нсамбля можно, используя любую регрессионную функцию потерь. Квадратичные потери выше - просто наиболее типичный случай.
Тогда шагу градиентного спуска при минимизации L(u)
u:=u−ε∇L(u)
будет приближённо соответствовать обновление ансамбля:
Gm(x):=Gm−1(x)+εfm(x),
где шаг обуч�ения (learning rate) ε>0 выбирается пользователем (гиперпараметр).
Если настройка ансамбля производится не минимизацией функции потерь, а максимизацией функции выигрыша, то fm(x) нужно настраивать приближать не антиградиент потерь (градиент со знаком минус), а градиент функции (со знаком плюс).
Примеры
Случай регресии
Рассмотрим задачу регрессии y∈R с функцией потерь:
L(G,y)=21(G−y)2
Тогда следующая базовая модель будет настраиваться приближать
f(x)≈−∂G∂L(G,y)=−(G−y)=(y−G)
Обновление базовой модели пройдёт по правилу
Gm(xn):=Gm−1(xn)+εf(x)≈Gm−1(xn)+ε(yn−Gm−1(xn))
То есть в каждой точке xn ансамбль будет корректироваться на величину недопрогноза yn−Gm−1(xn).
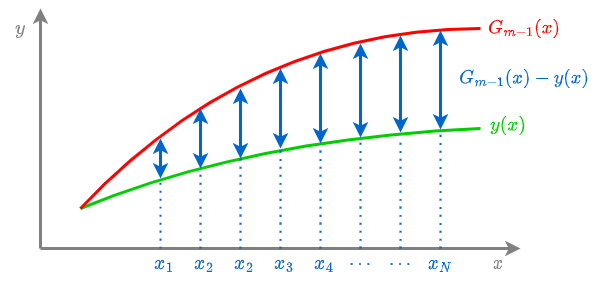
Случай бинарной классификации
Для бинарной классификации y∈{+1,−1} зададим функцию потерь персептрона:
L(G,y)=max{−Gy,0}
Тогда следующая базовая модель будет настраиваться приближать
fm(x)≈−∂G∂L(G,y)={y,0,Gy<0Gy≥0
Gm(xn):=Gm−1(xn)+εfm(x)≈Gm−1(xn)+{εyn,0,G(xn)yn≤0G(xn)yn>0
В результате такого обновления ансамбль не изменяется для объектов, которые уже классифицируются корректно (G(xn) и yn одного знака), и изменится на ε в сторону yn на неверно классифицированных объектах.
Это улучшает качество классификации неверно предсказанных объектов (повышает отступ), поскольку конечные прогнозы ансамбль выдаёт по правилу:
y^(x)={+1,Gm(x)>0,−1,Gm(x)<0.
Это изменение проиллюстрировано ниже:
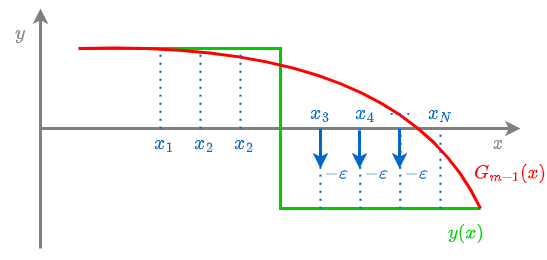
Как видим, при использовании функции потерь персептрона корректировка на ε осуществляется только для ошибочно классифицированных объектов, у которых y(x) и Gm−1(x) разных знаков.
Случай многоклассовой классификации
Для многоклассовой классификации можно использовать методы один-против-одного, один-против-всех и коды, исправляющие ошибки, которые решают многоклассовую классификацию с помощью набора бинарных классификаторов.
Альтернативно можно решать многоклассовую классификацию напрямую. В этом случае Gm−1(x)∈RC будет представлять собой уже вектор из рейтингов для каждого из C классов, а в качестве прогноза будет назначаться класс, обладающий максимальным рейтингом:
y^=argc∈{1,2,...C}maxGm−1,c(x)
В случае минимизации потерь L(⋅):
fm(xn)≈−∂G∂L(Gm−1(xn),yn)∈RC,
то есть базовая базовая модель и целевая величина будут представлять собой C-мерные векторы, сближаемые через векторную функцию потерь.
Далее мы рассмотрим алгоритм бустинга в общем виде.
С частным случаем многоклассового бустинга при логистической функции потерь можно ознакомиться, например, в [3].
Литература
-
Wikipedia: gradient boosting.
-
Friedman J. H. Greedy function approximation: a gradient boosting machine //Annals of statistics. – 2001. – С. 1189-1232.
-
Мерков А. Б. Распознавание образов: введение в методы статистического обучения. // Москва: Едиториал УРСС. – 2019.