Алгоритм градиентного бустинга
Базовый алгоритм
Разобравшись в идее построения каждой следующей базовой модели в градиентном бустинге, приходим к следующему алгоритму построения итогового ансамбля:
Вход:
-
обучающая выборка ;
-
функция потерь и число базовых моделей .
-
Настраиваем начальное приближение по .
-
Для каждого :
-
вычисляем градиенты:
-
настраиваем на выборке ;
-
обновляем .
-
Выход: композиция .
Алгоритм с переменным шагом
Шаг обучения можно варьировать, подбирая его наилучшее значение на каждой итерации, решая задачу одномерной оптимизации (например, простым перебором по сетке):
Вход:
-
обучающая выборка ;
-
функция потерь и число базовых моделей .
-
Настраиваем начальное приближение по .
-
Для каждого :
-
вычисляем градиенты:
-
настраиваем на выборке ;
-
настраиваем шаг
-
обновляем
-
Выход: композиция .
Модификация для решающих деревьев
Когда базовыми алгоритмами выступают решающие деревья (что и применяется почти всегда на практике), то алгоритм немного изменяется. Как известно, решающее дерево разбивает пространство признаков на систему непересекающихся прямоугольников , соответствующих листьям дерева. Каждому листу (и соответствующему прямоугольнику) назначается константный прогноз , как показано на иллюстрации:
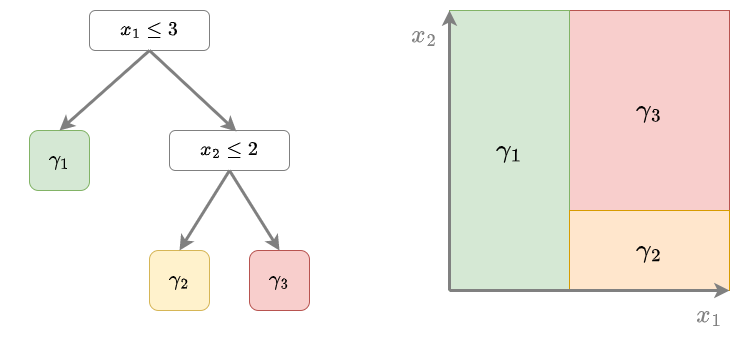
Прогноз решающего дерева имеет вид:
После настройки решающего дерев�а на шаге 2.ii, предлагается индивидуально подобрать прогнозы для каждой соответствующей области признакового пространства, чтобы они лучше всего улучшили качество работы ансамбля:
Вход:
-
обучающая выборка ;
-
функция потерь и число базовых моделей .
-
Настраиваем начальное приближение по .
-
Для каждого :
-
вычисляем градиенты: ;
-
настраиваем решающее дерево на выборке , получаем разбиение пространства признаков ;
-
для каждого прямоугольника пересчитываем прогнозы:
-
обновляем .
-
Выход: композиция .
Обратим внимание, что в этой схеме отсутствует подбор коэффициента при базовой модели. Учёт коэффициента мог бы синхронно изменять все прогнозы добавляемого решающего дерева в каждом прямоугольнике. Но необходимости в этом нет, поскольку мы у�же подобрали индивидуальные прогнозы в каждом прямоугольнике на шаге 2.iii.
Также с реализацией градиентного бустинга и особенностью реализации для решающих деревьев можно ознакомиться в [1].
Пример запуска на Python
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import brier_score_loss
X_train, X_test, Y_train, Y_test = get_demo_classification_data()
# инициализация модели (базовые модели-по умолчанию деревья, но могут быть другие):
model = GradientBoostingClassifier(n_estimators=1000, # число базовых моделей
learning_rate=0.1, # шаг обучения
subsample=1.0, # доля случайных объектов для обучения
max_features=1.0) # доля случайных признаков для обучения
model.fit(X_train, Y_train) # обучение модели
Y_hat = model.predict(X_test) # построение прогнозов
print(f'Точность прогнозов: {100*accuracy_score(Y_test, Y_hat):.1f}%')
P_hat = model.predict_proba(X_test) # можно предсказывать вероятности классов
loss = brier_score_loss(Y_test, P_hat[:,1]) # мера Бриера на вер-ти положительного класса
print(f'Мера Бриера ошибки прогноза вероятностей: {loss:.2f}')
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_absolute_error
X_train, X_test, Y_train, Y_test = get_demo_regression_data()
# инициализация модели (базовые модели-по умолчанию деревья, но могут быть другие):
model = GradientBoostingRegressor(n_estimators=1000, # число базовых моделей
learning_rate=0.1, # шаг обучения
subsample=1.0, # доля случайных объектов для обучения
max_features=1.0) # доля случайных признаков для обучения
model.fit(X_train, Y_train) # обучение модели
Y_hat = model.predict(X_test) # построение прогнозов
print(f'Средний модуль ошибки (MAE): \
{mean_absolute_error(Y_test, Y_hat):.2f}')
Больше информации. Полный код.