Обучение графовых нейросетей
Генерация минибатчей
Графовые нейросети, как и другие другие виды нейросетей, обучаются на минибатчах для ускорения обучения за счёт его параллелизации.
Классификация/регрессия графа целиком
Распараллелить вычисления на задачах классификации/регрессии графов напрямую не удаётся, поскольку каждый граф имеет собственную структуру с различным числом узлов и рёбер между ними. Для одновременной обработки нескольких графов их можно объединить в один мета-граф (состоящий из несвязанных друг с другом обучающих графов), применить к нему алгоритм обмена сообщениями, а регрессию/классификацию применить к каждому отдельному графу мета-графа.
Классификация/регрессия отдельных узлов
При классификации/регрессии отдельных узлов графа перед стартом алгоритма передачи сообщений нужно выбрать минибатч из случайных вершин графа, для которых будет происходить обновление их эмбеддингов. Если алгоритм использует итераций, то выделение каждой вершины будет предполагать выделение подграфов, состоящих из всех вершин, имеющих расстояние, не превосходящее до заданной, поскольку каждая итерация расширяет область видимости (receptive field) вершины на один переход по графу. Остальные вершины можно игнорировать, поскольку они не будут оказывать влияние на формирование эмбеддингов выбранных вершин.
Если исходный граф обладает высокой связностью, а достаточно велико, то подграфы минибатча будут слишком большими, зачастую покрывая весь исходный граф целиком. Чтобы этого не происходило, можно использовать два подхода:
-
Вырезать минимальное число рёбер, чтобы разбить исходный граф на нужное число несвязанных подграфов (graph partitioning [1]). Для этого есть стандартные алгоритмы из теории графов, такие как Metis [2] и Graclus [3], вырезающие минимальное число рёбер графа, чтобы он разделился на несвязные компоненты. После такой минимально инвазивной процедуры вершины минибатчей будут разрастаться уже не до всего графа целиком, а максимум - только до соответствующей компоненты связности. Эта процедура была предложена для повышения эффективности обучения графовых сетей в [4]. Пример разбиения графа на несвязные компоненты показан ниже:
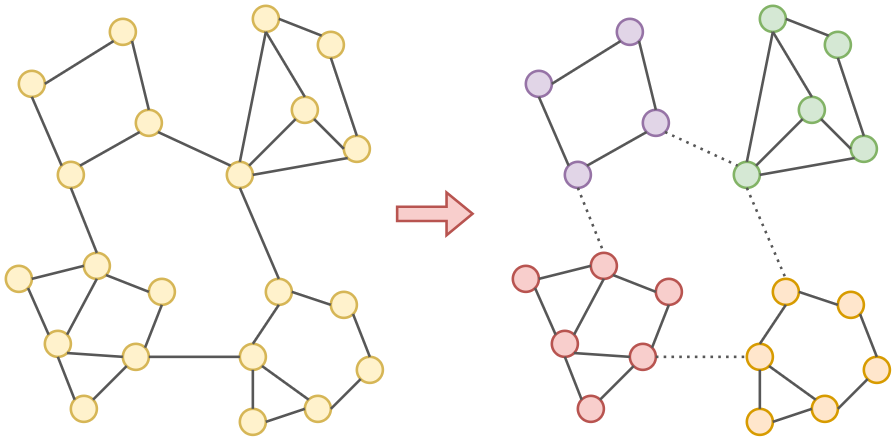
-
Использовать случайных соседних вершин вместо всех, а выбрать достаточно малым, чтобы не выйти из ограничений по памяти. Этот подход называется сэмплированием окрестности (neighborhood sampling [5]) и проиллюстрирован ниже [5]:
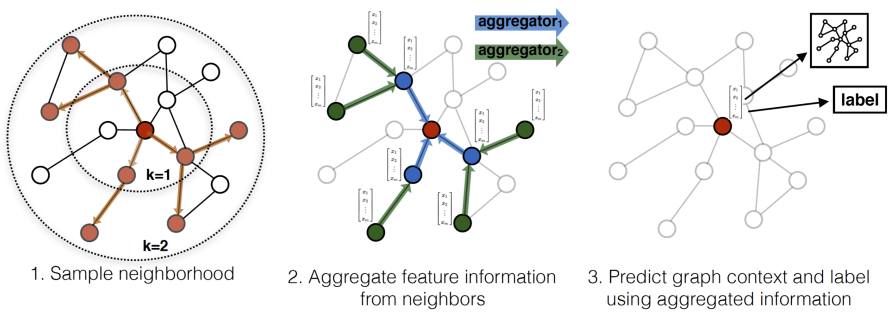
Регуляризация
Для избежания переобучения в графовых сетях можно использовать регуляризацию точно так же, как и в обычных, накладывая, -/-регуляризацию на веса модели и сокращая число нейронов и слоёв. Также можно делать параметры преобразований на каждой итерации алгоритма передачи сообщений одинаковыми (weight sharing) и использовать сэмплирование окрестности (neighborhood sampling [5]).
Литература
- Wikipedia: Graph partition.
- Karypis G., Kumar V. A fast and high quality multilevel scheme for partitioning irregular graphs //SIAM Journal on scientific Computing. – 1998. – Т. 20. – №. 1. – С. 359-392.
- Dhillon I. S., Guan Y., Kulis B. Weighted graph cuts without eigenvectors a multilevel approach //IEEE transactions on pattern analysis and machine intelligence. – 2007. – Т. 29. – №. 11. – С. 1944-1957.
- Chiang W. L. et al. Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks //Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. – 2019. – С. 257-266.
- Hamilton W., Ying Z., Leskovec J. Inductive representation learning on large graphs //Advances in neural information processing systems. – 2017. – Т. 30.