Cвёрточные графовые сети
Cвёрточные графовые сети (graph convolutional networks) реализуют пересчёт исходных признаковых описаний соответствующих вершин , учитывая контекст, то есть признаковые описания соседних вершин. Пересчёт производится много раз, начиная с и получая для каждой вершины .
Рассмотрим свёртку, действующую на однослойном (чёрно-белом) изображении:
где - смещение, а - веса для соседних пикселей.
Специфика свёртки на графах:
-
используется информация только с непосредственных соседних вершин;
-
нет понятий верхнего, нижнего, правого и левого соседей.
Граф может быть повёрнут, но это будет тот же самый граф!
Пересчёт старых эмбеддингов вершин графа в новые производится по формулам:
где
-
- функция, агрегирующая информацию с соседних вершин;
-
- функция, обновляющая информацию о текущей вершине, используя её информацию с предыдущей итерации и агрегированную информацию о её соседях.
Функция должна быть определена для любого числа соседей и не должна зависеть от порядка их обхода, чтобы обеспечить свойство инвариантности к перенумерации вершин. Применение операций Aggregate, а затем Update представляет собой одну итерацию алгоритма обмена сообщениями (message passing neural network [1]), который использует несколько итераций, а начальные значения для вершин определяются их начальными эмбеддингами: Если не заданы, то их можно инициализировать one-hot закодированным значением числа соседей узла или геометрическими характеристиками вершин (число соседей 1-го, 2-го порядка, меры центральности вершин на графе и т. д.)
Алгоритм передачи сообщений представлен ниже:
ВХОД:
ненаправленный граф
начальные эмбеддинги вершин
функции и
АЛГОРИТМ:
для :
ВЫХОД:
- итоговые эмбеддинги вершин
Применение итераций алгоритма обмена сообщениями аналогично применению свёрточных слоёв при обработке изображений. Функции Aggregate и Update имеют свои настраиваемые параметры, причём в общем случае они свои на каждой итерации алгоритма.
Каждая итерация алгоритма передачи сообщений - это слой глубокой графовой сети.
Обратим внимание, что каждая итерация алгоритма повышает область видимости (receptive field) результирующего эмбеддинга на один переход по графу аналогично тому, как его повышает последовательное применение свёрток. Это проиллюстрировано ниже для отдельной вершины.
Нулевая итерация (начальный эмбеддинг):
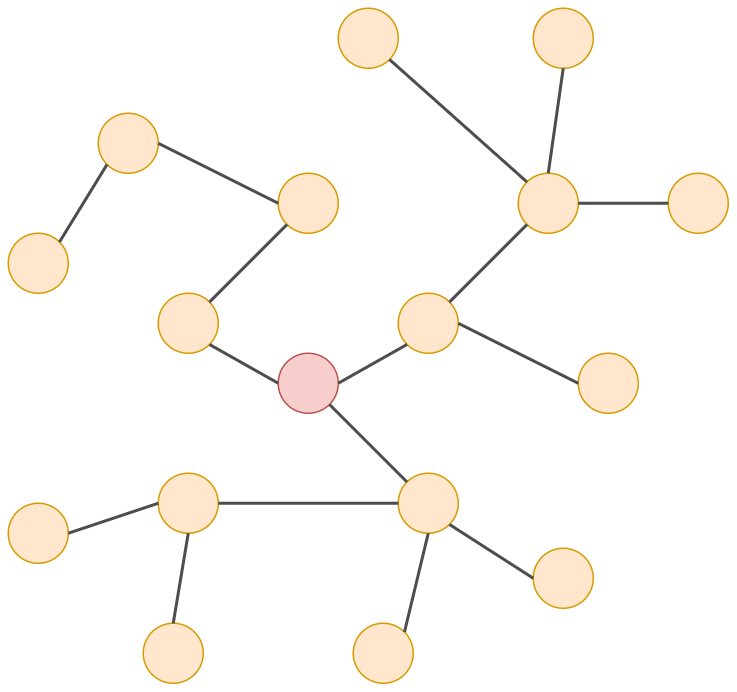
Первая итерация:
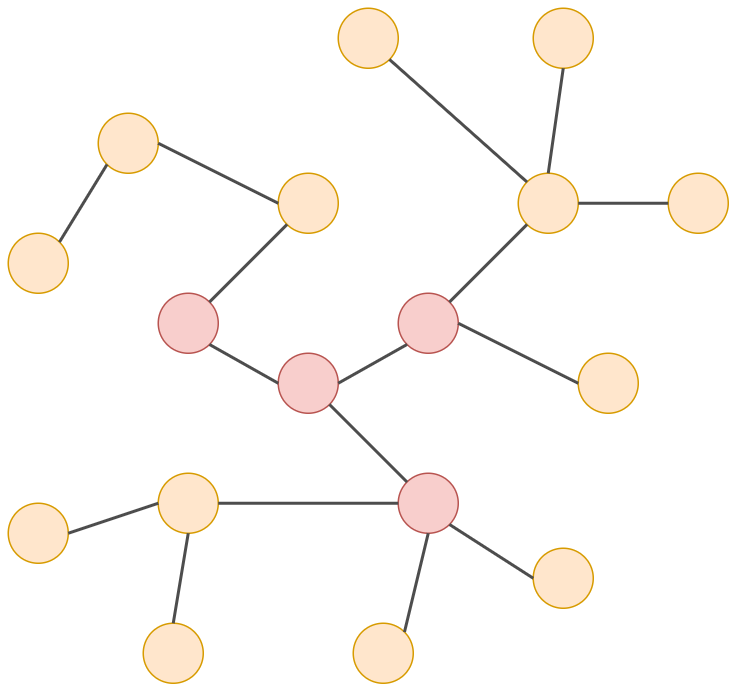
Вторая итерация:
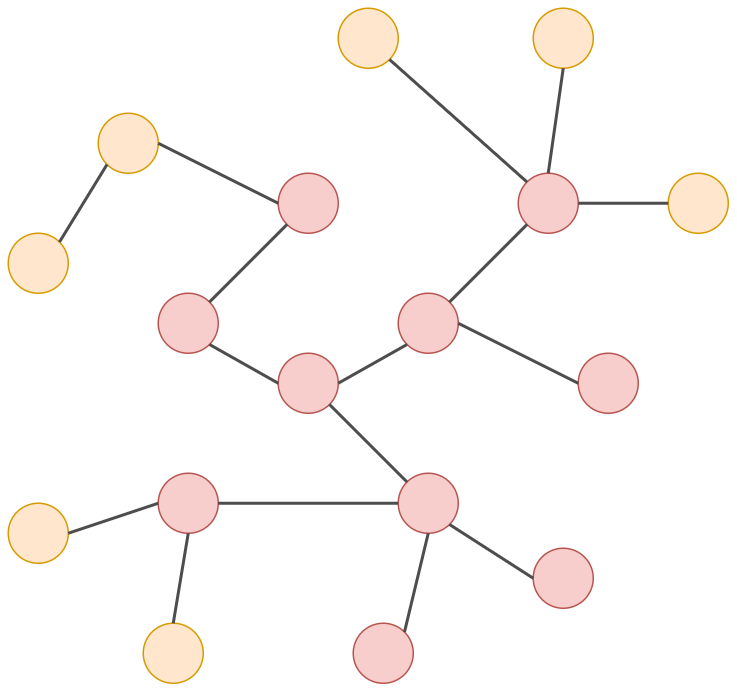
Третья итерация:
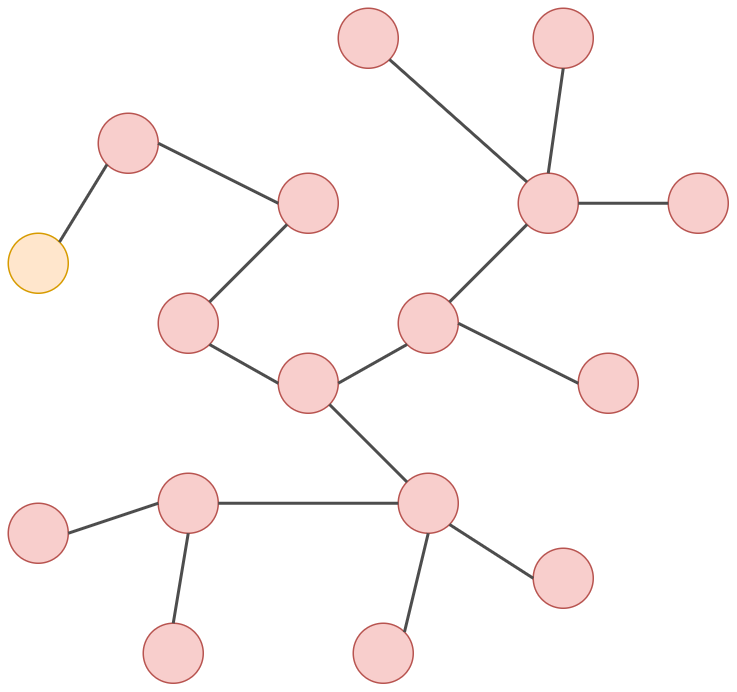
Если граф имеет недостаточную связность, то сообщения между вершинами распространяются медленно. В этом случае связность можно искусственно повысить, добавив в граф дополнительную вершину, связанную со всеми остальными (super-node).
Агрегирующая функция
Функцию Aggregate можно определять по-разному, лишь бы она была определена для любого числа соседей и не зависела от порядка их обхода. Самый простой вариант - сумма эмбеддингов:
где - множество индексов вершин, соединённых ребром с вершиной .
Также можно использовать усреднение:
Усреднение по сравнению с суммой работает более устойчиво на вершинах, содержащих сильно различающееся число соседей. Но оно, в отличие от суммы, не способно учитывать зависимость от числа соседей, поскольку при усреднении эта информация теряется.
Также можно усреднять, учитывая различия в числе соседних узлов у каждого соседа [2]:
Эмпирически при многократной агрегации на последних слоях алгоритма обмена сообщениями эмбеддинги получаются слишком сглаженными (over-smoothed) за счёт многократных усреднений. Предотвратить этот эффект можно, используя в качестве агрегации поэлементный максимум:
Наиболее общим видом усреднения, способным моделировать любую дифференцируемую зависимость, инвариантную к перенумерации вершин, является использование двух многослойных персептронов (multi-layer perceptron, MLP) со своими настраиваемыми векторами параметров и [3]:
В последней формуле вместо суммы можно использовать и другие перечисленные выше виды агрегации.
Агрегация со вниманием
Можно использовать механизм внимания (attention mechanism) при агрегации узлов [4] аналогично тому, как он использовался в рекуррентных сетях.
Для этого нужно произвести следующие действия:
-
Вычисляется внимание, с которым узел должен смотреть на каждого своего соседа , используя некоторую функцию :
-
Коэффициенты внимания пропускаются через SoftMax-преобразование:
-
Агрегация информации с узлов осуществляется пропорционально найденному вниманию:
Например, внимание может вычисляться через билинейную форму с настраиваемой матрицей :
В более общем случае внимание может вычисляться через многослойный персептрон:
Графовые сети с механизмом внимания называются graph attention networks (GAT).
Аналогично тому, как это сделано в трансформере, можно применять несколько головок внимания со своими весами, конкатенировать полученные результаты и приводить результат к исходному -мерному пространству эмбеддингов, используя линейный слой.
Обновляющая функция
Типичным способом определения функции Update является использование одного линейного слоя:
где - функция активации, применяемая поэлементно. Популярный способ передачи сообщений - агрегировать суммированием и использовать одну и ту же матрицу весов для целевого узла и его соседей:
Чтобы облегчить настройку параметров сети, а также частично избавиться от сглаживания эмбеддингов (когда они становятся слишком похожими за счёт повторного усреднения по ним) можно использовать в качестве выхода сумму преобразования с исходным входом (остаточный блок), как было в модели ResNet:
Альтернативно в качестве итогового представления каждой вершины можно использовать конкатенацию её представлений на всех итерациях передачи сообщений:
Тогда даже при сглаживании на последних итерациях эмбеддинги вершин всё равно будут существенно различаться за счёт учёта эмбеддингов с более ранних итераций.
С учётом признаков с разных слоёв сети мы уже сталкивались в модели DenseNet.
Инвариантность к перенумерациям
В матричном виде операции Aggregate и Update можно описать цепочкой преобразований
где
-
- матрица смежности вершин,
-
- матрица, столбцы которой являются внутренними представлениями узлов на -м шаге алгоритма обмена сообщениями;
-
- матрица начальных эмбеддингов вершин;
-
- матрица настраиваемых весов на -м шаге.
На каждом шаге алгоритма передачи сообщений преобразование должно обладать эквивариантностью к перенумерации узлов (equivariance) - если вершины перенумеровать, то и результат их обработки должен перенумероваться соответствующим образом.
Запишите в матричном виде описанные выше операции Aggregate и Update. Для операций усреднения вам понадобится матрица степеней. Для каждой записи в матричном виде докажите, что для неё выполнено свойство эквивариантности. Для этого вам пригодятся формулы пересчёта матрицы данных, матрицы смежности и матрицы, обратной к матрице степеней при перенумерации вершин графа.
Учёт эмбеддингов рёбер и всего графа
Алгоритм передачи сообщений в графе можно обобщить, чтобы он обновлял и учитывал в обновлении не только эмбеддинги вершин , но также эмбеддинги рёбер и всего графа целиком (general message passing [5]).
Обобщённый алгоритм передачи сообщений:
ВХОД:
ненаправленный граф
начальные эмбеддинги вершин
начальные эмбеддинги рёбер
начальный эмбеддинг графа
функции и
АЛГОРИТМ:
для :
ВЫХОД:
- итоговые эмбеддинги
Как видим, алгоритм состоит из следующих шагов:
-
обновляются эмбеддинги каждого ребра по его старому эмбеддингу, эмбеддингам вершин ребра и графа целиком;
-
обновляется эмбеддинг контекста каждой вершины по эмбеддингам связанных с ним рёбер;
-
происходит обновление эмбеддинга вершины по её старому эмбеддингу, контексту и эмбеддингу всего графа;
-
обновляется эмбеддинг всего графа, используя его старый эмбеддинг и агрегацию по обновлённым эмбеддингам вершин и рёбер.
Учёт взаимных влияний признаков вершин, рёбер и графа целиком позволяет моделировать сложные взаимодействия, решая весь комплекс задач на графах:
-
предсказание свойств узлов;
-
предсказание свойств рёбер;
-
предсказание свойств графа целиком.
Далее мы рассмотрим особенности обучения графовых сетей и изучим геометрические способы извлечения эмбеддингов вершин графа, не использующие никаких внешних признаков вершин, а учитывающие только их геометрическое расположение на графе.
Литература
- Gilmer J. et al. Neural message passing for quantum chemistry //International conference on machine learning. – PMLR, 2017. – С. 1263-1272.
- Kipf T. N., Welling M. Semi-supervised classification with graph convolutional networks //arXiv preprint arXiv:1609.02907. – 2016.
- Zaheer M. et al. Deep sets //Advances in neural information processing systems. – 2017. – Т. 30.
- Veličković P. et al. Graph attention networks //arXiv preprint arXiv:1710.10903. – 2017.
- Battaglia P. W. et al. Relational inductive biases, deep learning, and graph networks //arXiv preprint arXiv:1806.01261. – 2018.