Модель SSD
Архитектура
Ранее описанная модель YOLO для детекции объектов на изображении работает на признаках, полученных после двух полносвязных слоёв, применённых к активациям последнего свёрточного слоя. Поскольку этот слой даёт карту признаков в низком пространственном разрешении, то качество детекции малых объектов было невысоким. Также на эту карту признаков накладывалась сетка размера 7x7, извлекающая объекты, поэтому максимальное число потенциально детектируемых объектов не могло быть больше 49.
Модель SSD (Single Shot Detector [1]) исправляет оба этих ограничения за счёт того, что детекция осуществляется с разных свёрточных слоёв.
-
Активации более глубоких слоёв имеют более обширную область видимости (receptive field), поэтому способны извлечь более крупные объекты.
-
А с помощью более ранних слоёв (более высокого пространственного разрешения) удаётся задетектировать более мелкие объекты.
Поскольку объекты детектируются на разных слоях, то максимальное число потенциально выделяемых детектором объектов методом SSD значительно больше, чем у YOLO.
Ниже приведено сравнение архитектуры SSD (сверху) и YOLO (снизу) [1]:
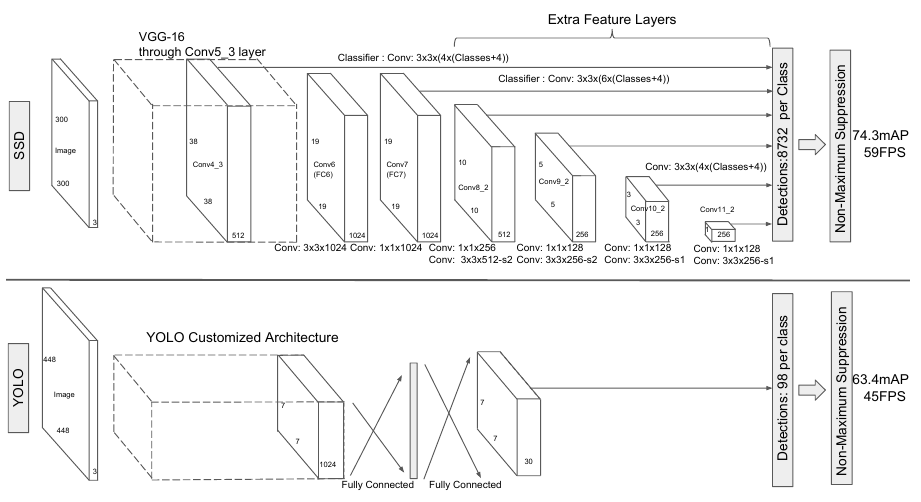
Последний слой SSD выделяет объекты, за которым обязательно следует модуль подавления немаксимумов.
Это важно, так как количество детекций будет избыточным вследствие того, что каждый объект может быть неоднократно выделен с разных слоёв.
Детекция в SSD осуществлялась не сразу, а после некоторого количества свёрточных слоёв, извлекающих более информативные признаки. Первыми слоями бралис�ь слои сети VGG-16, предобученной для задачи классификации.
Прогнозирование
Начиная с определённого уровня, на каждом слое действовали свёртки 3x3, предсказывавшие значения для каждой позиции на карте признаков.
Для каждой позиции:
-
рассматривались шаблонных рамок (шаблон, anchor box), в качестве которых рассматривались 9 вариантов: большая/малая/средняя по размеру и квадратная/вытянутая вбок/вытянутая вверх по форме;
-
вероятностей классов для каждой шаблонной рамки;
-
четыре смещения для позиции левого верхнего угла выделяющей рамки и смещений ширины и высоты относительно шаблонной рамки.
Примеры детекций кошки и собаки для трёх шаблонных рамок проиллюстрированы ниже [1]:
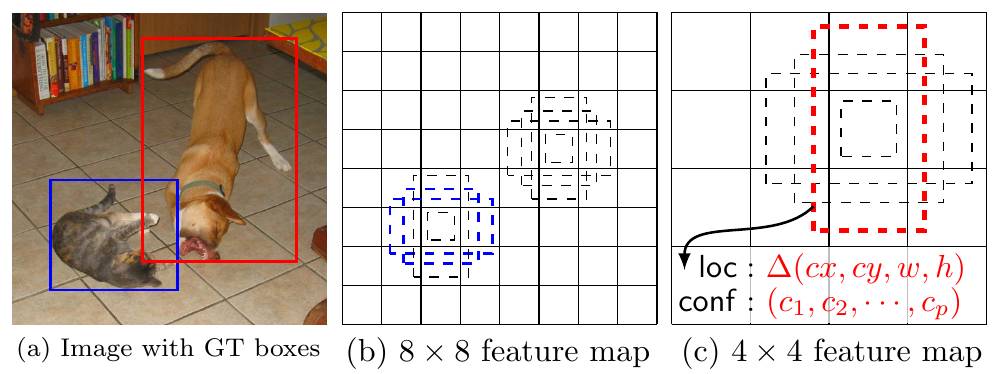
В примере кошка была извлечена с более раннего свёрточного слоя рамкой, вытянутой вбок, а собака - с более позднего слоя рамкой, вытянутой вниз.
Настройка модели
Модель настраивалась, минимизируя взвешенную сумму функции потерь классификации (classification loss, точность определения класса рамки) и потерь локализации (localization loss, точность расположения самой рамки).
Поскольку каждый объект может быть локализован многократно с разных слоёв и используя разные шаблонные рамки, правильные выделения объектов в функции потерь соотносились лишь с одним выходом сети, соответствующим шаблонной рамке, максимально похожей по мере IoU на правильную.
Ошибки локализации считались только для выходов сети, соотнесённых правильным рамкам. При локализации использовались сглаженные потери (smooth L1 loss), а целевыми переменными выступали не абсолютные, как у YOLO, а относительные ошибки локализации рамки по отношению к координатам и размеру шаблонной рамки.
Этот приём позволил существенно повысить точность локализации и является стандартным в методах детекции, использующих шаблонные рамки (anchor based methods). Нейросети проще предсказать поправку относительно хорошей гипотезы, чем напрямую само значение координат.
Ошибки классификации вычислялись кросс-энтропийной функцией потерь, причём они считались только для выходов сети, соотнесённых правильным рамкам, а также для ложных выделений несуществующих объектов (настраиваясь на фоновый класс).
В последнем случае брались не все такие случаи, а лишь те, в которых модель была сильнее всего уверена, что объект там есть. Этот подход называется hard negative mining и используется для того, чтобы выровнять количество корректных и некорректных выделений. Без этого приёма фоновых детекций было значительно больше, чем детекций реальных объектов! Это позволяет сосредоточить обучение модели на уточнении детекций объектов только целевых классов.
При настройке активно использовалась аугментация данных (data augmentation), существенно повысившая точность модели. В качестве аугментации использовались отражения изображения вдоль горизонтальной оси, выделение фрагмента на исходном изображении и на уменьшенной версии изображения, расширенного паддингом (padding).