Модель RetinaNet
Модель RetinaNet [1] - метод детекции объектов на изображениях, который существенно обогнал в качестве работы модели YOLO v1 и SSD.
В этой модели использовалась нейросеть FPN для генерации представлений изображения в разном разрешении.
Используя эти представления, удалось производить детекцию как в малых, так и в больших пространственных разрешениях, эффективно выделяя как большие, так и малые объекты соответственно. Причём детекторы на каждом слое работали над сложными информативными признаками.
Схема модели RetinaNet [1]:
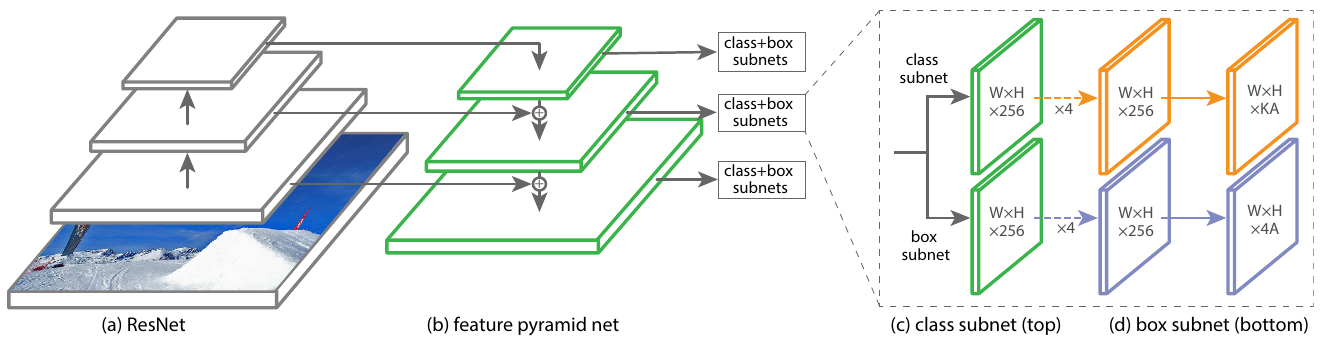
К каждому слою декодера FPN-сети применялись две независимые сети:
-
детектор (классифицирующий рамки),
-
локализатор (корректирующий расположение рамок относительно шаблона, как в SSD).
Подсети детектора и локализатора работали со своими параметрами. Таким образом, локализация формально не зависела от детекции.
При этом к каждому декодировочному слою FPN применялись детектор и локализатор с одними и теми же параметрами.
Классификатор и локализатор представляли собой последовательное применение четырёх свёрток 3x3 с постобработкой функцией активации ReLU.
Классификаторы и локализаторы для каждой позиции применялись раз для шаблонных рамок (anchor boxes). Рассматривались рамки
-
малого, среднего и большого размера;
-
вытянутые по горизонтали, квадратные и вытянутые по вертикали.
Это давало вариантов для каждой пространственной позиции.
Выходы классификатора и локализатора
Последней нелинейностью в классификаторе была сигмоидная активация, чтобы выдавать вероятности каждого из детектируемых классов. Таким образом, классификатор выдавал выходов. Если все активации были близки к нулю, то это трактовалось как отсутствие объекта.
Последней нелинейностью в локализаторе была тождественная функция, после которой локализатор выдавал выходов: смещение по вертикали и горизонтали относительно центра шаблонной рамки, а также изменение её стандартной ширины и высоты.
Функция потерь
Сопоставление детекций
Поскольку в каждой пространственной позиции для шаблонных рамок предсказываются рамки и классы объектов, для расчёта функции потерь необходимо сопоставить предсказанные детекции с реальными.
Предсказанные детекции сопоставлялись реальным, если мера IoU их пересе�чения была выше 0.5. Если же она была ниже 0.4, то сопоставлялся фоновый класс (отсутствие объекта). Случаи IoU в функции потерь игнорировались.
Типы потерь
В модели RetinaNet, как и во всех других методах детекции объектов, использовалась функция потерь, равная сумме двух компонент:
-
функции потерь локализации (определение местоположения объектов)
-
функции потерь классификации (корректность определения класса)
В качестве функции потерь локализации использовалась функция потерь Хубера, как дифференцируемая и устойчивая к выбросам.
Классификатор выдавал независимых вероятностей классов (рейтингов, пропущенных через сигмоиду). Фоновому классу отвечала ситуация, когда вероятности всех выделяемых классов близки к нулю. Каждый выход классификатора можно было бы настраивать бинарной кросс-энтропийной функцией потерь:
где - индикатор присутствия целевого класса. Однако в RetinaNet используются более эффективные сфокусированные потери (focal loss), описанные далее.
Focal loss
Авторы модели RetinaNet обратили внимание, что на большинстве детекций присутствуют выделения отсутствующих объектов (рамки, выделяющие фоновый класс, то есть отсутствие каждого из целевых классов). При этом объектов целевых классов на каждом изображении сравнительно немного.
Рамки, отвечающие отсутствующим объектам, классифицируются фоновым классом достаточно уверенно. Но за счёт того, что число рамок фонового класса существенно превосходит число рамок целевых классов, оптимизация нейросети сосредотачивается не на улучшении обнаружения целевых классов, а на повышении уверенности распознавания отсутствующих объектов как фонового класса!
Для того, чтобы этого не происходило, в RetinaNet предлагается новый вид потерь классификации - сфокусированные потери (focal loss), ставшие впоследствии очень популярными:
где
-
- вероятность реализации (одного из целевых классов);
-
- вероятность отсутствия этого класса (если для всех классов , то объект отсутствует и реализуется фоновый класс);
-
- гиперпараметр метода.
Указанные потери суммируются для всех рамок и всех целевых классов.
По смыслу домножение на снижает вклад в совокупные потери обнаружений с высоким уровнем уверенности в классе, а домножение на снижает вклад обнаружений с высоким уровнем уверенности в присутствии фона.
За счёт такого перевзвешивания большое количество обнаружений фона перестаёт доминировать в общей сумме, что позволяет оптимизации сети лучше сосредоточиться на повышении качества распознавания именно целевых классов. Также акцент оптимизации смещается с дальнейшего повышения вероятностей уверенно классифицированных классов на те, в которых модель недостаточно уверена.
Ниже показан пример влияния дополнительного множителя на логарифм вероятности целевого класса [1]:
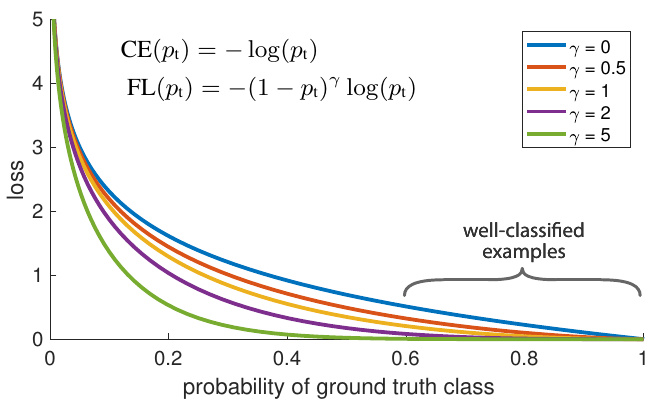
Как видно из графика, потери уменьшаются при существенно быстрее, чем для стандартных кросс-энтропийных потерь.
В работе предлагалось брать , а вес каждого слагаемого в focal loss дополнительно домножался на веса, понижающие вклад частотных целевых классов.
Потери focal loss позволили существенно повысить качество распознавания объектов и стали использоваться во многих последующих алгоритмах детекции.