Сеть пирамидальных признаков (FPN)
Архи�тектура FPN
Сеть пирамидальных признаков (feature pyramid network, FPN, [1]) - это не просто улучшенный метод детекции объектов, а целая концепция более эффективного извлечения признаков из изображений, которая может применяться и в других задачах обработки изображений. В случае детекции она привела к улучшению качества модели Faster R-CNN.
Ниже показано сравнение архитектур извлечения признаков в моделях YOLO (a), SSD (b) и в предложенной модели FPN (c) [1]:
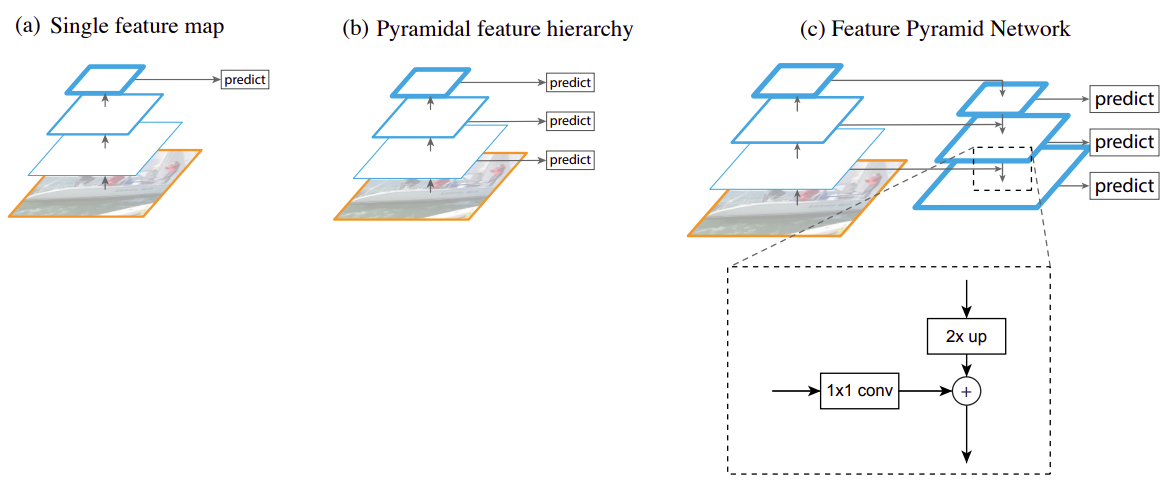
Левая часть во всех архитектурах использует свёрточные слои одной из успешных сетей для классификации изображений, таких как VGG и ResNet, которые можно дообучить для задачи детекции. Каждый вышестоящий слой извлекает всё более сложные признаки, при этом пространственное разрешение с каждым следующим слоем понижается. Серию преобразований с понижением пространственного разрешения будем называть кодировочной частью (кодировщик, encoder).
В архитектуре YOLO (a) детектор работает на последнем свёрточном слое, что позволяет точно определять тип объекта, но его координаты определяются неточно из-за низкого пространственного разрешения используемых карт признаков (feature maps). Также у YOLO возникают проблемы с детекцией малых объектов, различимых лишь в высоком разрешении.
Эти трудности были отчасти преодолены в архитектуре SSD (b), где детекция производилась на разных промежуточных представлениях изображения. Однако качество этой детекции на более ранних слоях было невысоким из-за того, что на этих слоях извлекались несложные признаки, такие как границы и другие простейшие паттерны.
В архитектуре FPN (c) предлагается дополнить левую кодировочную часть с понижением пространственного разрешения декодировочной частью (декодировщик, decoder) с повышением разрешения, а детекцию производить на разных слоях декодировочной части. На схеме (c) выше она показана справа.
В сети FPN в декодировщике пространственное разрешение повышается на каждом слое одним из методов повышения разрешения (в оригинальной статье использовалась интерполяция ближайшим соседом). Для того, чтобы лучше сохранить информацию о расположениях объектов, соответствующее внутреннее представление из кодировочной части прибавлялось к внутреннему представлению декодировочной части, что на рисунке показано горизонтальными связями между слоями.
Перед прибавлением внутреннее кодировочное представление обрабатывалось свёрткой 1x1, чтобы выходное число каналов совпало с числом каналов представления в декодировщике.
В декодировщике на каждом слое использовалось одно и то же число каналов (256), поскольку на каж�дом слое впоследствии применялась одна и та же модель детекции. Результат суммы представлений в кодировщике и декодировщике обрабатывался свёрткой 3x3, чтобы сгладить артефакты интерполяции при повышении разрешения, после чего результат передавался на следующий слой декодировщика.
Преимущества архитектуры FPN
Использование внутренних представлений декодировщика FPN даёт следующие преимущества:
-
Поскольку детекция производится на разных слоях декодировочной части с разным пространственным разрешением, то детектор сможет хорошо извлекать как большие объекты (с малых пространственных разрешений), так и малые (с больших пространственных разрешений). Мы это уже видели в методе SSD, но там детекция производилась по промежуточным представлениям кодировочной части.
-
Независимо от используемого слоя декодировочной части, признаки будут сложными и информативными, поскольку они интегрируют в себе признаки, полученные с последнего слоя кодировочной части. Это позволит детектору извлекать сложные объекты независимо от слоя, на котором он работает.
В архитектуре FPN предлагалось производить детекцию серией одинаковых свёрточных слоёв (независимо от слоя декодировщика), настроенных распознавать класс и уточнять координаты выделяющей рамки (bounding box) относительно таких же шаблонных рамок (anchor boxes), которые использовались в SSD.