Использование весов другой сети
Жесткий перенос весов (hard weight sharing)
Предположим, нам нужно решить узкоспециализированную задачу A, такую как распознавание модели машины по её фотографии. Как правило, когда заходит речь о задаче с узкой специализацией, то данных для настройки модели оказывается мало, поскольку сбор объектов �и их ручная разметка - это трудоёмкий процесс. Зато можно воспользоваться другой похожей задачей B, данных для которой много, и есть уже настроенные и хорошо зарекомендовавшие себя модели.
Например, можно воспользоваться датасетом ImageNet, содержащим свыше 14 миллионов размеченных изображений на 1000 классов, содержащих типовые объекты, встречаемые на практике, такие как кошки, собаки, машины, грузовики, дома, прицепы, компьютеры и т.д. Для этого датасета уже существует большой набор настроенных моделей. Классы ImageNet хотя и не совсем соответствуют решаемой задаче определения марки машины по её фото, но в целом и та, и другая задача опираются на похожий набор признаков - чтобы распознать марку машины, нужно вначале извлечь углы распознаваемого предмета, определить его цвет, извлечь типовые графические паттерны, отвечающие резине колёс, бликам на стеклах, цветовым переливам на форме кузова. А эти признаки как раз и извлекаются в уже настроенных моделях на ImageNet.
Поэтому, вместо того, чтоб�ы обучать модель под целевую задачу с нуля рекомендуется вначале извлечь информативные высокоуровневые признаки из промежуточных слоёв уже настроенных моделей на ImageNet, как показано ниже:
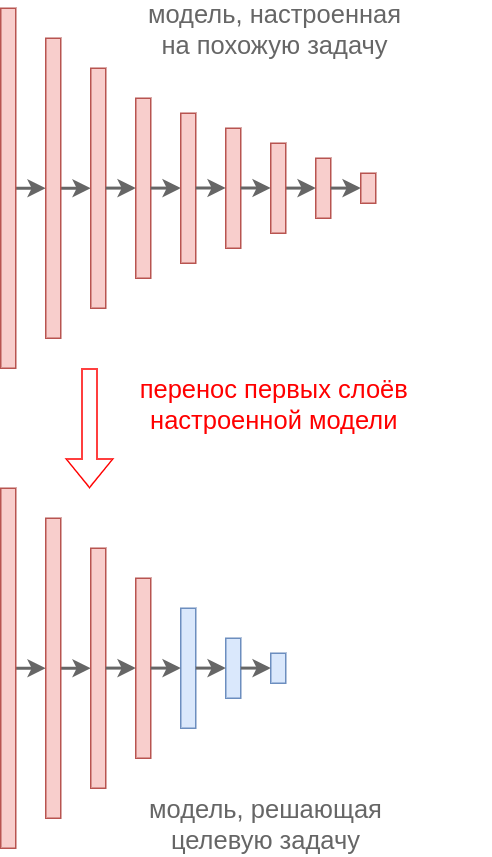
Таким образом, веса первых слоёв модели, решающей задачу B (красные), переносятся в неизменном виде на первые слои модели, решающие задачу A. Это называется жёсткая общность весов (hard weight sharing). Под целевую задачу A настраиваются лишь последние слои (синие), что позволяет сэкономить на сложности настройки и обучиться на обучающей выборке меньшего объёма. Чем больше размеченных данных мы имеем для решения целевой задачи A, тем большее количество последних слоёв мы можем выделить для настройки под эту задачу.
Похожая задача B может как в точности повторять целевую задачу A, как в примере выше - и в первом, и во втором случае решается задача классификации, просто на немного различающихся изображениях и классах.
Но в качестве вспомогательной задачи B можно выбирать и другую задачу. Например, задача A - классификация изображений, а задача B - генерация изображений с помощью автокодировщика или генеративно-состязательной сети (в этом случае заимствуются первые слои дискриминатора). Другой задачей может быть определение одинаковости одинаковых версий изображений, повернутых на случайный угол и обрезанных, используя сиамские сети (instance discrimination). Преимущество использования задачи без учителя (unsupervised learning) заключается в том, что задача без учителя не использует ручную разметку и поэтому может обучаться на гораздо больших объемах данных, причем это могут быть те самые данные, на которых решается целевая задача A.
Мягкий перенос весов (soft weight sharing)
Поскольку задача A всё же несколько отличается от задачи B, то имеет смысл предположить, что и низкоуровневые признаки, перенесённые с первых слоёв должны как-то отличаться. Но несильно, поскольку задачи A и B похожи. Добиться этого можно двумя способами:
-
После переноса весов донастроить все веса модели, решающей целевую задачу, с малым шагом обучения (learning rate) небольшое число итераций. Такая донастройка их изменит, но несильно. Донастройку нужно производить как для ранних, так и для поздних слоёв, которые должны переприспособиться к обновлениям более ранних слоёв.
-
Как альтернатива, можно настраивать все веса с обычным шагом обучения, но с регуляризацией , препятствующей сильному отклонению весов целевой модели от весов референсной модели, решающей задачу .