Контрастное обучение
Определение
Контрастное обучение (contrastive learning [1]) настраивает отображение объекта в признаковое представление или эмбеддинг (embedding) таким образом, чтобы похожие объекты были близки, а непохожие - далеки друг от друга в пространстве эмбеддингов. При этом понятие похожести/непохожести определяется решаемой задачей.
Преобразование , отображающее объект в его эмбеддинг, на�зывается сиамской сетью (siamese network [1], [2]), поскольку при настройке точная копия этой сети будет применяться не к одному, а сразу к нескольким объектам.
При этом размерность пространства эмбеддингов обычно невелика и составляет несколько сотен признаков.
Примеры использования
Ниже приводятся примеры задач, решаемых с помощью контрастного обучения, и то, какие объекты считаются похожими и непохожими в каждой задаче:
| N | Задача | Похожие объекты | Непохожие объекты |
|---|---|---|---|
| 1 | классификация | принадлежат одному классу | принадлежат разным классам |
| 2 | проверка подписи человека по её отсканированной версии | подписи одного и того же человека | подписи разных людей |
| 3 | обнаружение перефразирования | перефразирования одной и той же фразы | перефразирования разных фраз |
| 4 | обнаружение одинаковых изображений | преобразования одного и того же изображения (поворот, обрезка, добавление шума, изменение цветов) | разные изображения |
В задачах 1, 2, 3 используется разметка, поэтому это задача обучения с учителем, известная как supervised contrasitve learning. Задача 4 - это задача обучения без учителя, поскольку внешняя разметка в ней не используется. Эта задача известна как instance discrimination.
Функция потерь контрастного обучения штрафует эмбеддинги похожих объектов за похожесть, а эмбеддинги непохожих объектов штрафует за непохожесть.
Ниже приведён пример эмбеддингов, построенных по задаче классификации рукописных цифр на датасете MNIST [3] и извлечённых с промежуточных слоёв обычной классификационной сети (слева) и с финальных слоёв сиамской сети (справа):
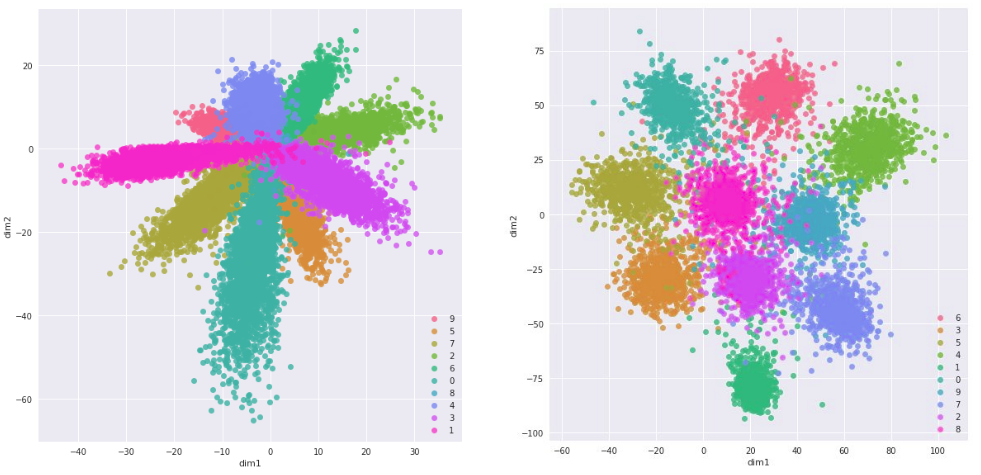
Похожими объектами выступают сканы одной и той же цифры, а непохожими - сканы разных цифр. Отвечающие эмбеддингам цифры обозначены цветом.
Как видим, эмбеддинги сиамской сети сильнее раздвинуты для объектов разных классов по сравнению с эмбеддингами обычной классификационной сети, что следует из функции потерь контрастного обучения, которые сближают эмбеддинги похожих объектов (объектов одного класса) и раздвигают эмбеддинги непохожих (разных классов).
После того, к�ак сиамская сеть настроена, можно решать конечную задачу метрическими методами в пространстве эмбеддингов, такими как метод ближайших центроидов или метод K ближайших соседей, поскольку эмбеддинги объектов разных классов будут далеко, а одного класса - близко.
Также можно использовать слои обученной сиамской сети для извлечения признаков для другой задачи (transfer learning).
Обработка объектов разных типов
Также контрастное обучение для обработки объектов разных типов. В этом случае каждый тип преобразуется в эмбеддинг своей нейросетью:
| Задача | Похожие объекты | Непохожие объекты |
|---|---|---|
| ранжирование, информационный поиск | поисковый запрос и соответствующие ему документы | поисковый запрос и нерел�евантные документы |
| построение текстового описания к изображению | изображение и соответствующее ему описание | изображение и не соответствующие ему описания |
| рекомендательные системы | пользователь и товары, которые ему понравились | пользователь и товары, которые ему не понравились или по которым нет данных |
Например, для рекомендательной системы будут настраиваться две нейросети и :
Различные преобразования и будут отображать объекты в общее пространство эмбеддингов, сохраняя свойство, что эмбеддинги соответствующих друг другу объектов должны быть близки, а не соответствующих - далеки друг от друга.
Далее пользователю можно рекомендовать те товары, эмбеддинги которых близки к эмбеддингу пользователя.
Аналогично можно реализовать информационный поиск, отображая в начале поисковой выдачи те документы, эмбеддинги которых максимально похожи на эмбеддинг поискового запроса.
Настройка сиамской сети
Рассмотрим для простоты обозначений обработку объектов одного типа с помощью сиамской сети, отображающей объект в его эмбеддинг:
Существуют три основные функции потерь для их настройки.
Попарные потери
При обучении с использованием попарных потерь (pairwise contrastive loss [4]) сэмплируются пары объектов , и происходит минимизация
В качестве обычно берётся Евклидово расстояние.
Гиперпараметр управляет минимальным расстоянием между непохожими объектами, при котором не будет штрафа. Его можно выбрать равным единице.
Поскольку сэмплируются всевозможные пары объектов, то число уникальных сэмплов будет , где - число объектов в обучающей выборке.
Тройные потери
При обучении, используя тройные потери (triplet loss [5]), сэмплируются тройки объектов:
-
- опорный объект (anchor);
-
- похожий на (положительный, positive);
-
- не похожий на (отрицательный, negative).
Сами тройные потери штрафуют ситуацию, когда эмбеддинги опорного и положительного объекта становятся слишком непохожими относительно различий эмбеддингов опорного и отрицательного объекта:
Поскольку сэмплируются тройки объектов, то число уникальных сэмплов будет иметь порядок .
Вероятностные потери
При обучении, используя вероятностные потери (InfoNCE loss, NCE=noise constrastive estimation, [6],[7]), сэмплируются
-
- опорный объект (anchor);
-
- похожий на (положительный, positive);
-
- набор непохожих на объектов (отрицательные, negatives).
Сами вероятностные потери имеют вид:
где - косинусная мера близости:
За счёт сэмплирования не одного, а целого набора из непохожих о�бъектов число уникальных сэмплов будет иметь порядок больше .
Указанные функции потерь можно применять и для объектов разных типов. В этом случае в формулах нужно подставлять эмбеддинги объектов, полученных из разных нейросетей, обрабатывающих соответствующие типы данных.
При классической настройке обычной сети по обучающей выборке из объектов существует всего уникальных сэмплов, по которым считается функция потерь. При контрастном оценивании число уникальных сэмплов гораздо больше, что позволяет настраивать сиамскую сеть точнее даже для небольших выборок!
Даже если есть всего один пример класса, то, сравнивая его с каждым из других объектов, уже получим уникальных сэмплов, поэтому контрастное обучение может эффективно использоваться в обучении всего по нескольким примерам класса (few-shot learning [8]).
Генерация обучающих примеров
Не ограничивая общности, рассмотрим задачу классификации, решаемую методом контрастного обучения. При генерации обучающих примеров можно сэмплировать равномерно
– по объектам;
– по классам (типам непохожести между объектами).
В перв�ом случае будут оптимизироваться микроусреднённые меры качества (на объектах), а во втором - макроусреднённые меры качества (на классах). Обычно требуется хорошо отделять каждый из классов, поэтому чаще используется второй подход.
Приёмы контрастного обучения можно использовать и для обучения расстояний (metric learning [9]), когда функция расстояния в метрических методах прогнозирования параметризуется, а параметры подбираются так, чтобы лучше решать конечную задачу. В случае задачи классификации можно подбирать такую меру близости (или расстояния) между объектами, чтобы объекты одного класса оказывались близки, а объекты разных классов - далеки друг от друга.
Детальнее о контрастном обучении и его приложениях можно прочитать в [10]. С библиотеками и последними статьями по теме можно ознакомиться в [11].