Ранняя остановка и зашумление входов
Ранняя остановка
Ранняя остановка (early stopping [1]) - другой пример ограничения нейросети, чтобы уменьшить её степень переобучения. Для этого нужно отслеживать потери модели по ходу обучения на валидационной выборке и заранее остановить обучение, когда потери на валидации начнут расти.
На графике ниже нужно остановить обучение сети по достижении пунктирной линии:
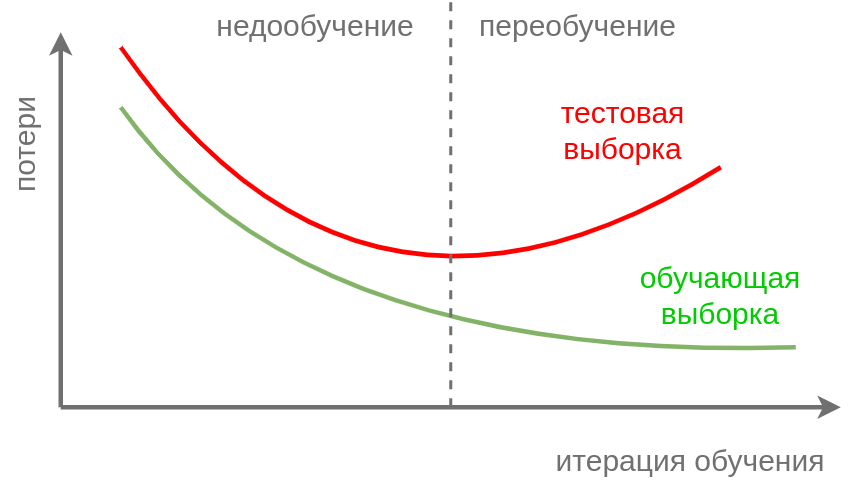
Эта стратегия объясняется тем, что вначале модель учится восстанавливать общую закономерность в данных, а начиная с некоторого момента её обобщающая способность начинает ухудшаться из-за переобучения под конкретную реализацию обучающей выборки.
Поэтому имеет смысл заранее прервать обучение, получив более простую и менее переобученную модель.
Зашумление данных
Другим приёмом упрощения модели служит её обучение на зашумлённых версиях объектов:
где - -мерный вектор случайных чисел (случайный шум), обладающий свойствами:
где - единичная матрица. При этом применение модели осуществляется на исходных данных без зашумления.
В [2] доказывается, что обучение регресии , минимизируя MSE-критерий на зашумлённых данных, эквивалентно обучению сети на незашумлённых данных с добавлением следующей регуляризации:
Таким образом, зашумление признаков требует от модели, чтобы изменение её прогнозов было менее резким при небольшом изменении вектора признаков , что отвечает реальным зависимостям в данных на практике.
В случае, когда - линейная регрессия, зашумление эквивалентно L2-регуляризации её весов.