Автоматическое прореживание сети
Идея
Ранее мы рассматривали регуляризацию нейросети путём упрощения её архитектуры вручную. Более эффективным подходом является автоматическое прореживание сети (automatic network pruning), то есть полное отбрасывание малозначимых фрагментов сети (связей, нейронов, наборов нейронов или целых слоёв) автоматическими средствами. Это проще и позволяет лучше подстроить прореживание под специфику изучаемых данных.
Детальный обзор методов прореживания нейросетей приведён в [1].
Преимущества
Прореживание нейросетей позволяет:
-
упростить нейросеть, чтобы бороться с переобучением и повысить обобщающую способность сети;
-
сократить число параметров, чтобы сеть занимала меньше памяти;
-
уменьшить энергопотребление ресурсоёмких вычислений;
-
использовать нейросеть на менее мощных процессорах (в телефоне, автономном роботе);
-
быстрее обрабатывать большие объемы информации (например, видеопоток);
-
увеличить масштабируемость модели, обрабатывая большее число пользовательских запросов.
Виды прореживания
По характеру прореживаемых блоков внутри сети методы прореживания сетей делятся на
-
неструктурированные (unstructured), когда исключаются отдельные связи за счёт зануления соответствующих весов;
-
структурированные (structured), в которых исключаются целые блоки нейросети, такие как нейроны (со всеми входящими и исходящими связями), а в случае свёрточных сетей - свёрточные каналы.
Свёрточным сетям посвящён отдельный раздел учебника. Пока достаточно знать, что прореживание может применяться и там.
Оба вида прореживания упрощают модель, уменьшая степень её переобученности. При хранении весов в разреженном формате (sparse format) прореженная сеть будет занимать меньше памяти.
Неструктурированные методы приведут к уменьшению числа вычислений, только если библиотека и оборудование поддерживают работу с разреженными данными. В противном случае будет производиться тот же объём вычислений, только с данными, содержащими много нулей, поскольку размеры перемножаемых тензоров от неструктурированного прореживания не изменятся.
Структурированные методы всегда приводят к уменьшению объёма вычислений, поскольку меняют размеры перемножаемых тензоров.
По времени прореживания относительно настройки модели они делятся на
-
прореживание до обучения (pruning before training);
-
прореживание во время обучения (pruning during training);
-
прореживание после обучения (pruning after training).
Схемы работы этих методов приведены на рисунке ниже, где модели выделены пунктиром, а действия - сплошной линией. Красным прямоугольником обозначена конечная модель.
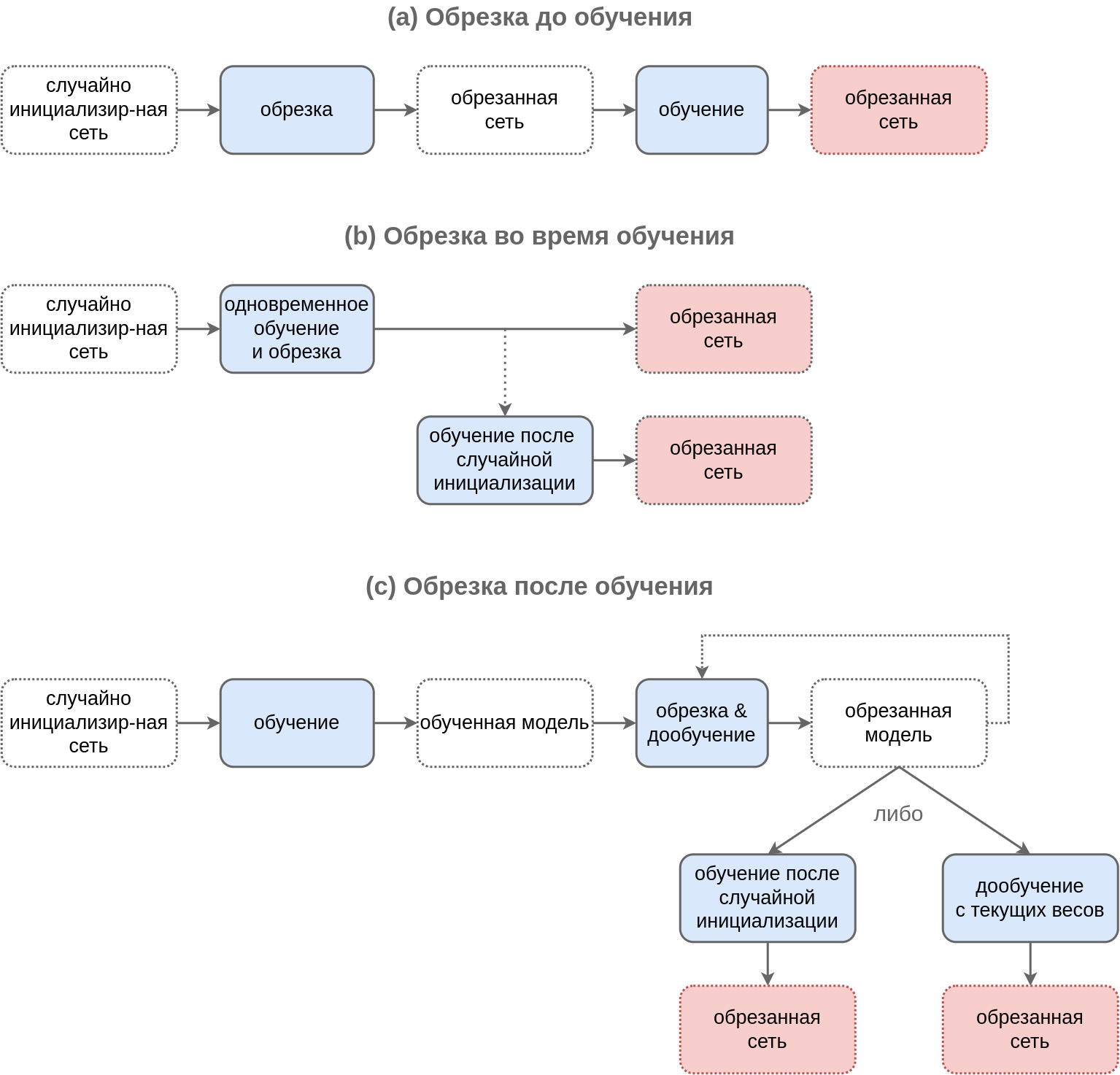
Прореживание до обучения
Прореживание до обучения (pruning before training) применяет алгоритм прореживания к случайно инициализированной большой сети. За счёт того, что обучение производится на прореженной сети, эффективность повышается как на этапе применения, так и на этапе обучения прореженной модели.
Вариант применения - произвести небольшое число итераций обучения сети до прореживания, а основной объём обучения производить уже после прореживания (pruning in early training), когда станет ясно, какие фрагменты сети важны, а какие - нет.
Прореживание после обучения
При прореживании после обучения (pruning after training) прореживание применяется к уже настроенной полной модели.
Если вычислительных ресурсов недостаточно, то результат прореживания представляет собой конечную модель, иначе можно улучшить результат, дообучив обрезанную модель либо с текущими весами, либо после их случайной реинициализации.
В разных исследованиях эти стратегии работают по-разному, но чаще первая работает лучше.
Если ресурсов на прореживание много, то оптимальнее повторить несколько итераций небольшого прореживания и донастройки нейросети, пока мы постепенно не дойдём до целевого уровня упрощения модели.
Методы прореживания
Самый простой подход прореживания заключается в оценке некоторой неотрицательной степени влияния связи или нейрона (или канала в свёрточной нейросети). Если эта степень влияния меньше порога, то соответствующие связь/нейрон/канал исключаются.
Оценкой влияния отдельной связи может служить абсолютная величина веса связи.
Оценкой влияния нейрона (как и канала в свёрточных сетях) служит -норма весов связей, входящих в нейрон либо исходящих из него. Аналогично можно считать важность каналов в свёрточных сетях.
Как альтернатива, можно ввести внешний настраиваемый множитель при нейроне/канале и оценивать общее влияние нейрона/канала по модулю этого множителя. Таким множителем, например, выступает параметр масштаба в батч-нормализации.
Представленные подходы обладают тем недостатком, что они локальны, т.е. не учитывают глобальное влияние на конечную функцию потерь. Может оказаться, что отдельные веса или нейроны, несмотря на слабость связей, в конечном итоге существенно влияют на окончательный прогноз за счёт больших весов при их последующей обработке.
Более целостной является глобальная степень влияния, т.е. насколько тот или иной элемент влияет на конечную функцию потерь. По смыслу - это изменение функции потерь, когда элемент включён и исключён �из нейросети.
Для оценки глобального влияния рассматривается модуль частной производной конечной функции потерь по весу (или мультипликатору при блоке нейросети), т.е. производится оценка того, насколько резко изменяется конечное качество прогнозов при изменении влияния отдельной связи/нейрона/блока сети.
Прореживание во время обучения
Прореживание во время обучения сети (pruning during training) обладает тем достоинством, что позволяет донастраивать веса с учётом прореженных связей, то есть из сети не просто исключаются элементы, но сеть при этом активно приспосабливается к этому прореживанию.
Для этого при настройке сети используется L1-регуляризация по весам или по множителям при блоках нейросети, которая известна тем, что зануляет отдельные элементы вектора, приводя к прореживанию:
где - исходная функция потерь на обучающей выборке.
Другие методы упрощения
Существуют и другие методы упрощения нейросетевых моделей:
-
квантизация нейросети (neural network quantization [2], [3]);
-
низкоранговая декомпозиция тензоров (low-rank tensor decomposition [4]);
При упрощении сетей эти методы активно совмещаются друг с другом и с автоматическим прореживанием, чтобы достичь максимального эффекта.
Литература
- Cheng H., Zhang M., Shi J. Q. A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations //IEEE Transactions on Pattern Analysis and Machine Intelligence. – 2024.
- Gholami A. et al. A survey of quantization methods for efficient neural network inference //Low-Power Computer Vision. – Chapman and Hall/CRC, 2022. – С. 291-326.
- Nagel M. et al. A white paper on neural network quantization //arXiv preprint arXiv:2106.08295. – 2021.
- Liu X., Parhi K. K. Tensor decomposition for model reduction in neural networks: A review [feature] //IEEE Circuits and Systems Magazine. – 2023. – Т. 23. – №. 2. – С. 8-28.
- Wikipedia: Knowledge distillation.
- v7labs.com: Knowledge Distillation: Principles & Algorithms.