Ограничение архитектуры
Сложные нейросети, содержащие большое число параметров, переобучаются на недостаточно больших обучающих выборках, поэтому их нужно упрощать. Для этого можно
-
использовать меньше слоёв;
-
использовать меньше нейронов;
-
использовать меньше входных признаков;
-
уменьшить число связей;
-
наложить ограничения на веса.
Уменьшение числа слоёв противоречит идеологии глубокого обучения по автоматической настройке информативных признаков за счёт увеличения числа слоёв нейросети. Однако в случае, когда реальная зависимость проста (например, линейна), а обучающих данных мало, это улучшает качество.
Уменьшение числа нейронов способно сильно упростить модель, особенно для многослойных персептронов, где связи между нейронами соседних слоёв устанавливаются по принципу каждый-с-каждым.
Уменьшение числа признаков - частный случай предыдущего подхода, когда уменьшается число нейронов входного слоя. Если просто сокращать объём известной информации, то качество м�ожет сильно ухудшиться. Поэтому, если хотим использовать мало признаков, то имеет смысл сгенерировать максимально информативную "выжимку" из исходных признаков путём их линейных и нелинейных преобразований (dimensionality reduction, feature engineering).
Например, если решается задача определения времени суток по фотографии, то вместо всего изображения можно подавать интеллектуальные признаки, имеющие связь с ответом, такие как положение солнца на фото и средняя яркость пикселей.
Уменьшение числа связей. Поскольку сложность модели зависит от числа настраиваемых параметров, отвечающих связям между нейронами, то можно упросить модель за счёт сокращения не числа нейронов, а числа связей между ними, сделав эти связи более разреженными (sparse connections).
Рассмотрим следующий многослойный персептрон, где для простоты опущены единичные нейроны.
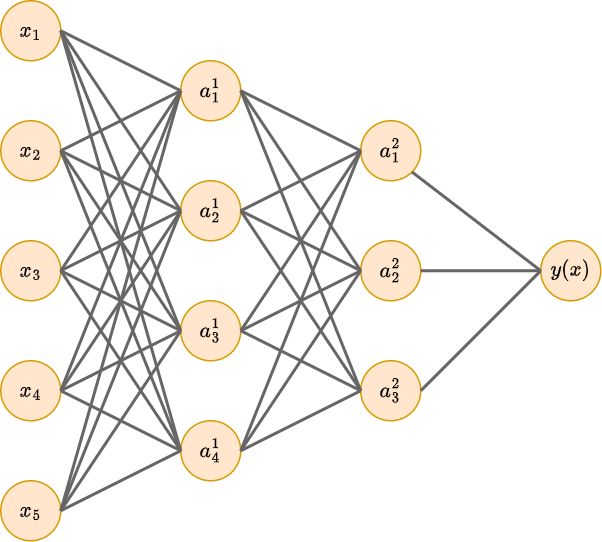
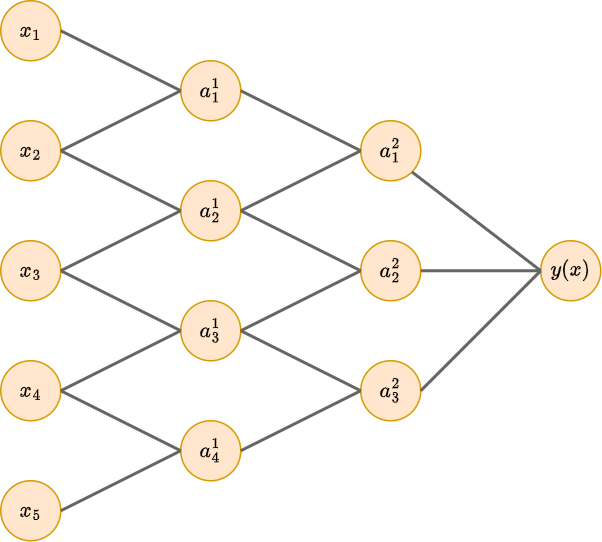
Сделав предположение, что каждый нейрон на первом и втором скрытом слое зависит только от двух своих соседей, получим существенное уменьшение числа связей (и, соответственно, настраиваемых весов):
Можно пойти дальше, и наложить ограничения на значения весов, например, предполагать их неотрицательность или связать веса друг с другом (weight sharing), чтобы они принимали одинаковые значения. Пример такого ограничения приведён на рисунке ниже, где на первом и втором слое связи с одинаковыми весами помечены одинаковым цветом:
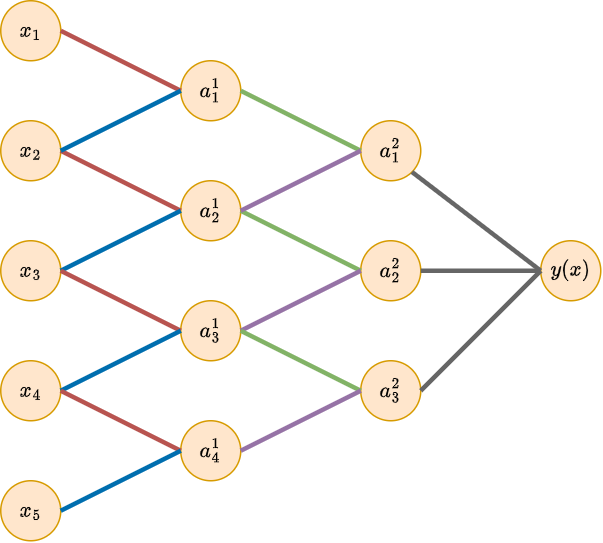
Подобное прореживание связей и привязка весов друг к другу используется в операции свёртки (convolution) для обработки последовательностей и изображений.
Мягкая связка весов (soft weight sharing)
Если точное приравнивание весов друг к другу слишком сильно снижает выразительную способность модели, то веса можно привязать друг к другу мягко (soft weight sharing) за счёт того, что мы позволим им принимать разные значения, но не сильно отличающиеся друг от друга. Это достигается ручной разбивкой весов на группы и добавлением в функцию потерь следующего регуляризатора
Чем выше гиперпараметр , тем более похожие значения будут принимать веса, находящиеся в одной группе.
В работе [1] предлагается автоматически распределить веса на группы, предположив, что априорно веса распределены как смесь из нормальных распределений (Гауссиан):
Взяв ло�гарифм со знаком минус, получим регуляризатор:
Для настройки модели с автоматическим разбиением весов на группы (и сближением весов в рамках каждой группы) достаточно включить этот регуляризатор в целевую функцию потерь:
При этом настройка будет вестись не только по весам модели, но и по параметрам регуляризатора, подстраивая степень сближения весов по данным.