Подходы к решению
Рассмотрим простые методы решения задачи семантической сегментации изображений и их ограничения.
Скользящее окно
Поскольку мы уже умеем решать задачу классификации изображений, то мы могли бы сопоставить каждому пикселю тот класс, который ему назначает классификационная сеть, если её применять к окрестности интересующего пикселя. Тогда для сегментации всего изображения пришлось бы просканировать изображение квадратной областью, вычисляя для каждого пикселя в центре области его класс.
Это очень неэффективное решение, поскольку требует производить классификацию столько раз, сколько пикселей на изображении. При этом классификатору пришлось бы пересчитывать одни и те же признаки для пересекающихся фрагментов.
Сеть из свёрток
Мы могли бы применить к изображению серию свёрток, как показано ниже [1]:
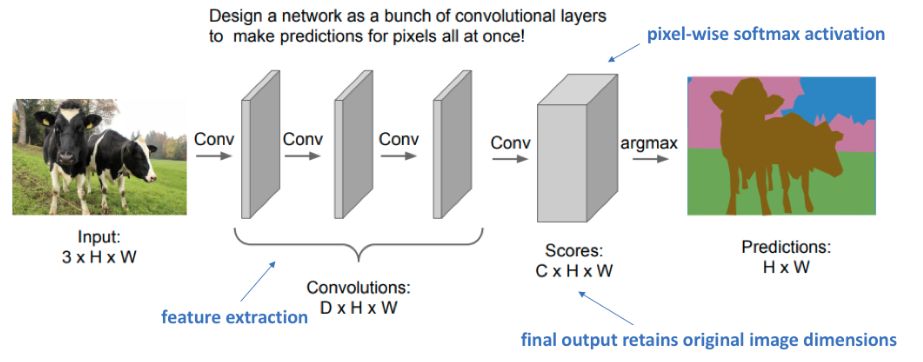
Каждая свёртка должна иметь шаг (stride) 1 и использовать паддинг вокруг границ (padding), чтобы размер выхода совпадал с размером входа.
Такой подход эффективнее, чем первый, поскольку признаки, извлекаемые на пересекающихся частях изображения, вычисляются однократно и переиспользуются.
Тем не менее, этот подход очень затратен по памяти и вычислениям, поскольку предполагает обработку тензоров высокого пространственного разрешения.
Кодировщик-декодировщик
Третий подход также использует свёрточную архитектуру, но предполагает постепенное уменьшение пространственного разрешения (spatial dimensionality reduction), а затем возврат к исходному разрешению, как показано ниже [1]:
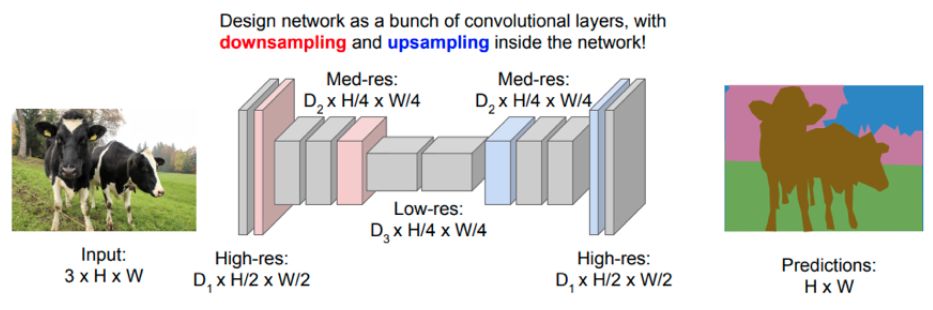
Благодаря �тому, что пространственное разрешение снижается, у нас появляется возможность эффективно произвести вычисление сложных признаков.
Свёрточные слои, на которых пространственное разрешение постепенно снижается, называются кодировщиком (encoder).
Классификационные сети векторизовали выход кодировщика и применяли к нему многослойный персептрон. Но в задаче семантической сегментации требуется выдать результат в виде тензора такого же пространственного размера, как входное изображение, поэтому далее к промежуточному представлению, полученному кодировщиком, применяется декодировщик (decoder), состоящий из специальных свёрточных блоков, повышающих пространственное разрешение (upsampling blocks).
Варианты реализации этих блоков будут рассмотрены в следующей главе.
Ограничение архитектуры
Ограничение предложенной архитектуры заключается в том, что мы по промежуточному представлению в низком разрешении (выходу кодировщика) пытаемся восстановить сегментационную карту в высоком разрешении. Это неизбежно будет приводить к потере пространственной информации и неточностям при восстановлении границ между классами!
Продвинутые методы сегментации, описанные далее, решают эту проблему, внося свои архитектурные дополнения в стандартную архитектуру кодировщика-декодировщика.