Модель U-net и её варианты
Базовая модель U-net
Архитектура U-net��
Модель U-net [1] осуществляет семантическую сегментацию, используя свёрточный кодировщик и декодировщик.
Кодировщик постепенно сжимает пространственное разрешение, применяя свёртки 3x3 без паддинга, а также используя пулинги 2x2 с шагом 2. Уменьшение разрешения частично компенсируется увеличением числа слоёв после каждого пулинга.
Декодировщик же постепенно увеличивает пространственное разрешение, используя соответствующие операции (upsampling) с одновременным уменьшением числа каналов. В декодировщике дополнительно применяются свёртки 3x3.
Проблема недостаточно точного восстановления границ из низкоразмерного промежуточного представления кодировщика решается тем, что внутренние представления кодировщика более высокого пространственного разрешения передаются на соответствующие слои декодировщика, как показано серыми линиями на схеме [1]:
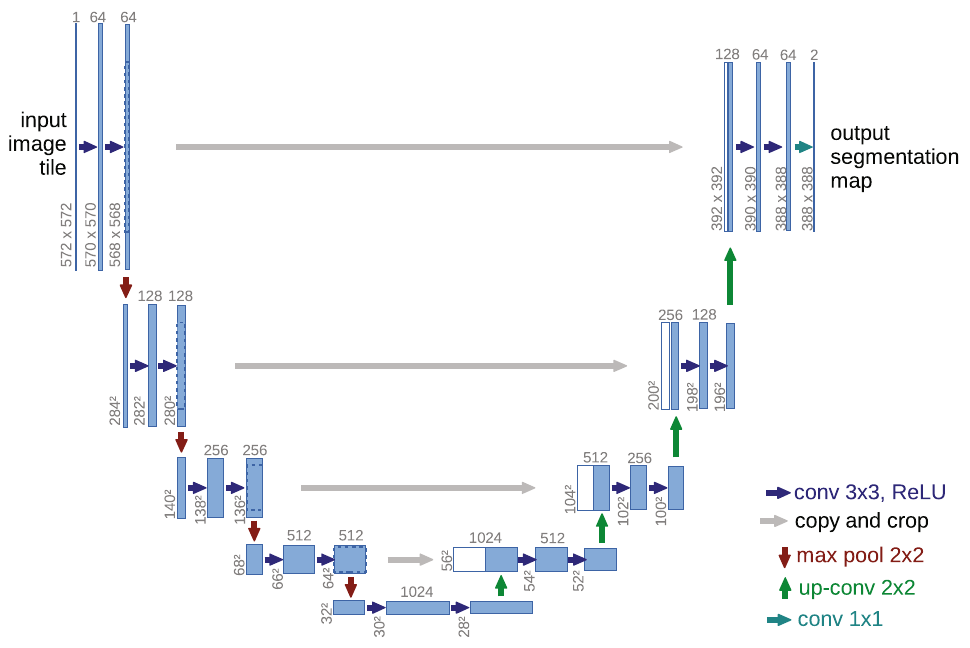
Объединение информации из декодировщика и кодировщика происходит путём конкатенации внутренних представлений вдоль каналов.
Выходом U-net является тензор , где
-
- высота и ширина сегментируемого изображения;
-
- число классов, включая фоновый (на схеме ).
К выходу для каждого пикселя применяется SoftMax-преобразование, чтобы получить вероятности классов. Модель настраивается, используя кросс-энтропийную функцию ошибки.
Поскольку в сети многократно применяются свёртки 3x3 без расширения, то пространственная размерность постепенно снижается на границах. Поэтому при переносе внутренних представлений с кодировщика они обрезаются по краям, чтобы конкатенировались тензоры одинакового пространственного размера.
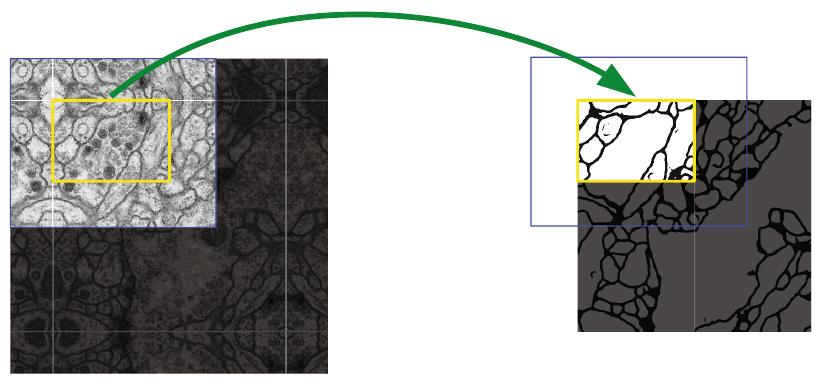
Для того, чтобы после всех свёрток на выходе получить ту же пространственную размерность, которой обладало сегментируемое изображение, входное изображение перед обработкой расширяется с помощью отражения пикселей по краям (mirror padding), как показано на рисунке [1]:
Настройка сети U-net
Сеть настраивается, используя принцип максимума правдоподобия, максимизируя взвешенное правдоподобие отнесения каждого пикселя к верному классу:
Вес учёта каждого пикселя считался по формуле
где
-
- гиперпараметры,
-
- вес класса (выше для более редких, чтобы классы вносили сопоставимый вклад в оптимизацию),
-
- минимальные расстояния до ближайших границ других двух классов.
Такое взвешивание позволило сильнее учитывать редкие классы, а также точнее выделять границы между областями разных классов, повышая значимость корректной классификации именно пограничных областей.
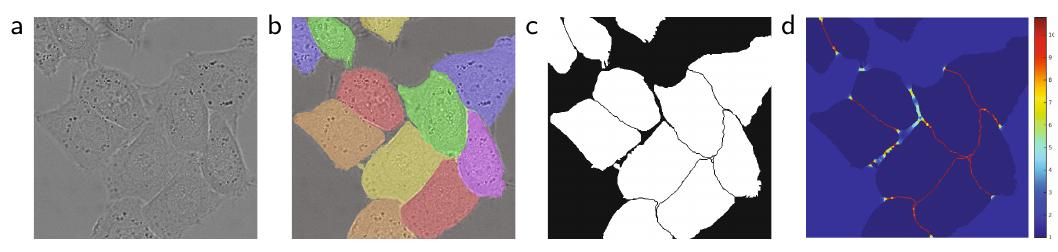
Ниже на графике (d) показана пространственная карта весов для сегментируемого изображения (a), корректной сегментации (b) сегментационной карты (с) и весов (d) [1]:
Архитектура U-net задала стандарт переноса промежуточн�ых представлений кодировщика в декодировщик, и сейчас этот принцип используется во многих задачах, где по входному изображению нужно сгенерировать выходное (image-to-image tasks).
Варианты архитектуры U-net
Рассмотрим варианты изменения архитектуры U-net для семантической сегментации.
LinkNet
Модель LinkNet [2] построена с целью упрощения вычислений и настройки модели по сравнению с U-net.
Архитектура LinkNet показана на рисунке [2]:
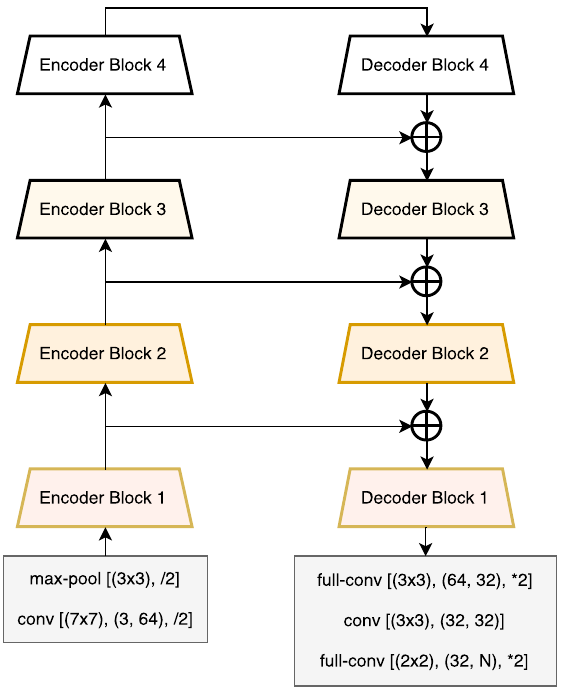
Она состоит из кодировщика (слева), на котором пространственное разрешение снижается на каждом блоке, и декодировщика (справа), каждый блок которого постепенно увеличивает разрешение, чтобы в конце вернуть его к разрешению исходного изображения.
Детализация каждого блока кодировщика и декодировщика прив�едена ниже [2]:
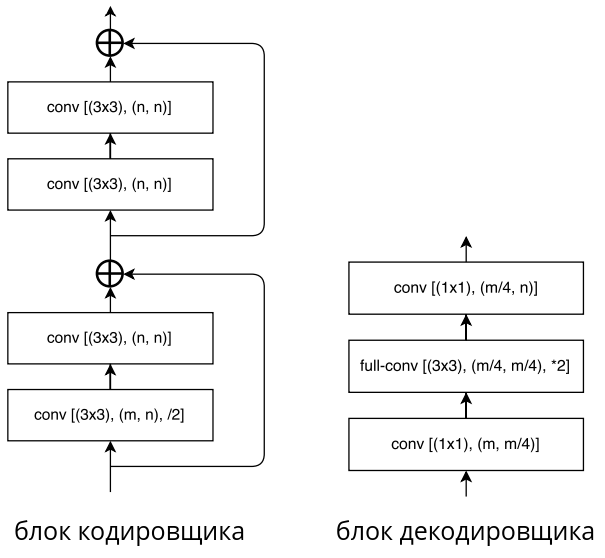
Здесь
-
conv [(AxA),(B,C)] обозначает свёрточный слой с ядром свёртки AxA, переводящий внутреннее представление из B в С каналов;
-
/2 означает уменьшение разрешения в 2 раза за счёт свёртки с шагом 2;
-
*2 означает увеличение разрешения в 2 раза.
Вычислительная эффективность LinkNet обеспечивается тем, что
-
промежуточные представления кодировщика не конкатенируются, а суммируются с промежуточными представлениями декодировщика;
-
в блоке декодировщика перед применением свёртки 3x3 действует слой свёрток 1x1, снижающий число каналов в 4 раза. После действия свёрток 3x3 число каналов возвращается к исходному также свёртками 1x1.
Для упрощения настройки сети в каждом блоке кодировщика используются ResNet-блоки. Тождественные связи этих блоков (с понижением разрешения) упрощают
-
перетекание информации об исходном изображении через кодировщик;
-
распространение градиента на ранние слои при настройке сети в методе обратного распространения ошибки.
One Hundred Layers Tiramisu
One Hundred Layers Tiramisu [3] также основана на идее U-net, но использует dense-блоки как базовые элементы.
Её архитектура представлена ниже [3]:
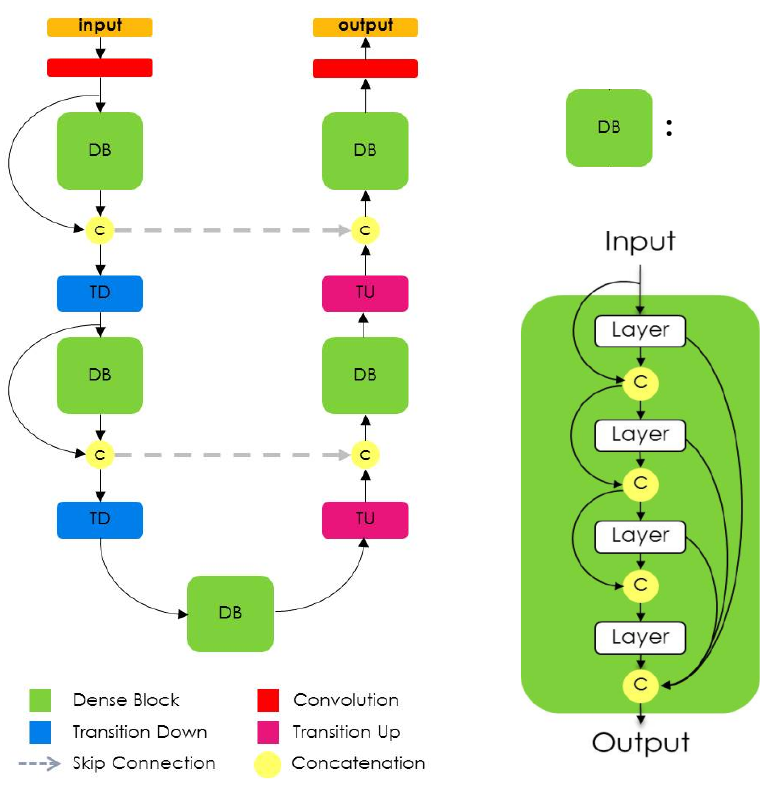
-
Блок Transition Down снижает разрешение в 2 раза, используя максимизирующий пулинг.
-
Блок Transition Up повышает разрешение в 2 раза, используя транспонированную свёртку.
Серые связи обозначают перенос промежуточных представлений кодировщика (слева) в декодировщик (справа). Объединение представлений производится не суммированием, как в LinkNet, а конкатенацией вдоль каналов, как в U-net.
Dense-блоки лучше сохранить информацию с более ранних представлений, поскольку она напрямую наследуется с более ранних слоёв (посредством конкатенации вдоль каналов). Это позволяет лучше сохранить информацию о первоначальном изображении для более точной итоговой сегментации.
За счёт конкатенаций внутренних представлений в dense-блоках и при переносе информации из кодировщика в декодировщик сети приходится обрабатывать повышенное число каналов. Поэтому сеть One Hundred Layers Tiramisu более требовательна к вычислениям, чем LinkNet, зато может обеспечить более высокую точность сегментации при достаточно большой обучающей выборке.
U-net++
Встроенная проблема методологии U-net заключается в том, что более низкоуровневые и простые признаки напрямую объединяются с более высокоуровневыми и сложными.
Для решения этой проблемы в архитектуре U-net++ [4] предложено вместо непосредственной конкатенации внутренних представлений кодировщика и декодировщика конкатенировать преобразованные представления кодировщика через dense-блоки, как показано ниже [4]:

Dense-блок призван приводить в семантическое соответствие более простые представления кодировщика с более сложными представлениями декодировщика.
Разница в семантической сложности выше для более высоких ярусов сети, поэтому там dense-блоки глубже. В этих блоках действует свёртка с нелинейностью, принимающая на вход конкатенацию всех предыдущих слоёв блока.
Архитектура U-net++ показала более высокое качество по сравнению с U-net [1].
Настройка сети велась, минимизируя сумму кросс-энтропийных потерь и коэффициента dice, причём потери считались по выходам всех верхних ярусов сети (принцип deep supervision). На выходе это позволяет считать прогнозы не только по , но и по урезанным версиям U-net++, выдающим прогнозы на слоях и .
Урезанные (prunned) версии сети показаны ниже [4]:
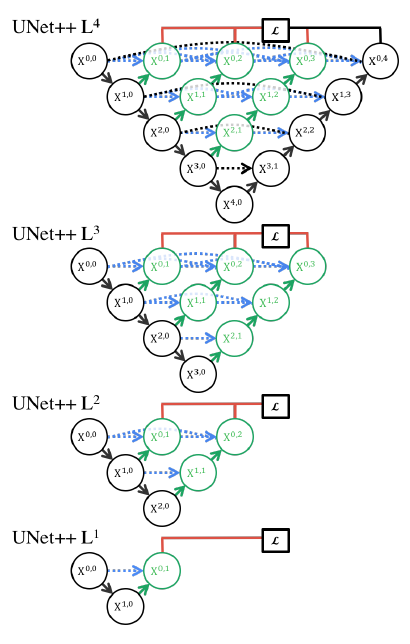
Более короткие версии U-net++ позволяют производить семантическую сегментацию менее точно, зато более быстро.
Литература
- Ronneberger O., Fischer P., Brox T. U-net: Convolutional networks for biomedical image segmentation //Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. – Springer International Publishing, 2015. – С. 234-241.
- Chaurasia A., Culurciello E. Linknet: Exploiting encoder representations for efficient semantic segmentation //2017 IEEE visual communications and image processing (VCIP). – IEEE, 2017. – С. 1-4.
- Jégou S. et al. The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation //Proceedings of the IEEE conference on computer vision and pattern recognition workshops. – 2017. – С. 11-19.
- Zhou Z. et al. Unet++: A nested u-net architecture for medical image segmentation //Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, September 20, 2018, Proceedings 4. – Springer International Publishing, 2018. – С. 3-11.