Семантическая сегментация
Задача семантической сегментации изображений (semantic segmentation) заключается в классификации каждого пикселя в зависимости от того, какой объект на нём изображён.
Пример семантической сегментации для случая трёх классов (человек, велосипед и фон) показан ниже [1]:
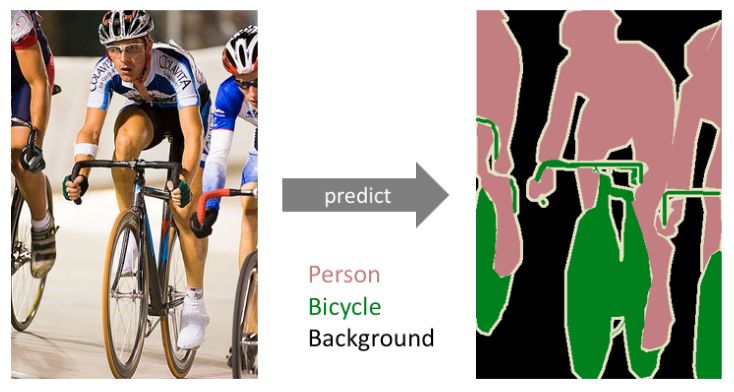
Обратим внимание, что в семантической сегментации разные представители класса не различаются. Поэтому в примере выше разные люди и велосипеды помечены одним классом. Это отличает семантическую сегментацию от сегментации объектов (instance segmentation), описанную далее в отдельном разделе.
Семантическая сегментация имеет многочисленные применения. Перечислим некоторые из них:
-
выделение на аэрофотоснимках городских застроек, сельскохозяйственных угодий и необработанных человеком участков местности;
-
сегментация болезненных участков на медицинских фотографиях и рентгеновских снимках;
-
сегментация людей и автомобилей с камер видеонаблюдения;
-
сегментация одежды на человеке для её замены в виртуальных примерочных (например, Amazon’s Virtual Mirror [2]).
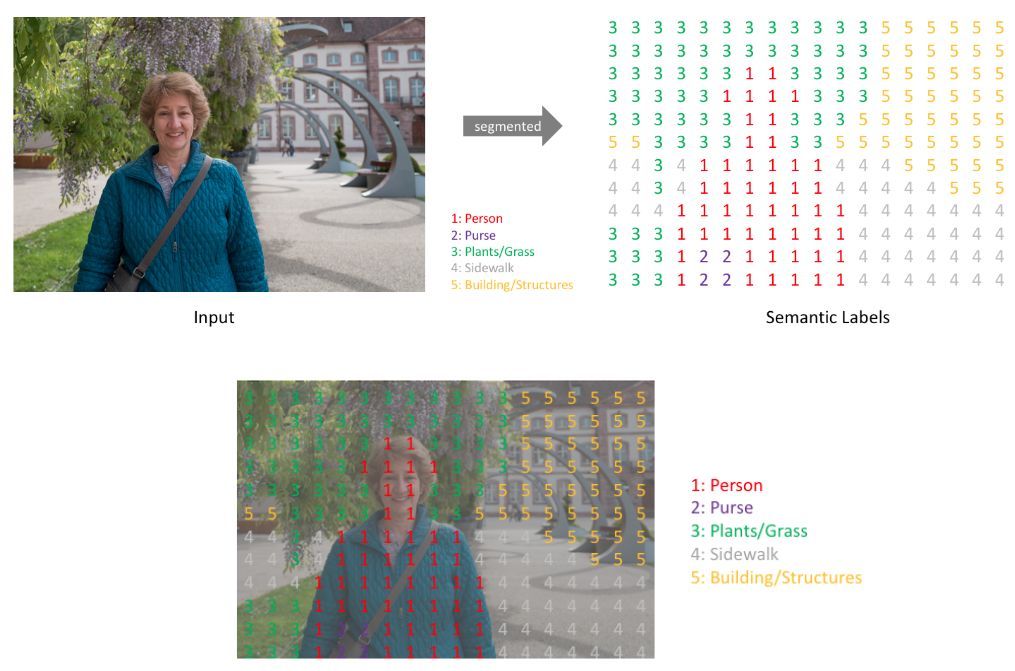
Желаемым выходом в задаче семантической сегментации является матрица того же пространственного размера, что и входное изображение, содержащая метки класса для каждого пикселя [1]:
Технически же сегментационная нейросетевая модель выдаёт тензор вероятностей классов размера , где - число классов, а и - пространственные размеры сегментируемого изображения [1]:
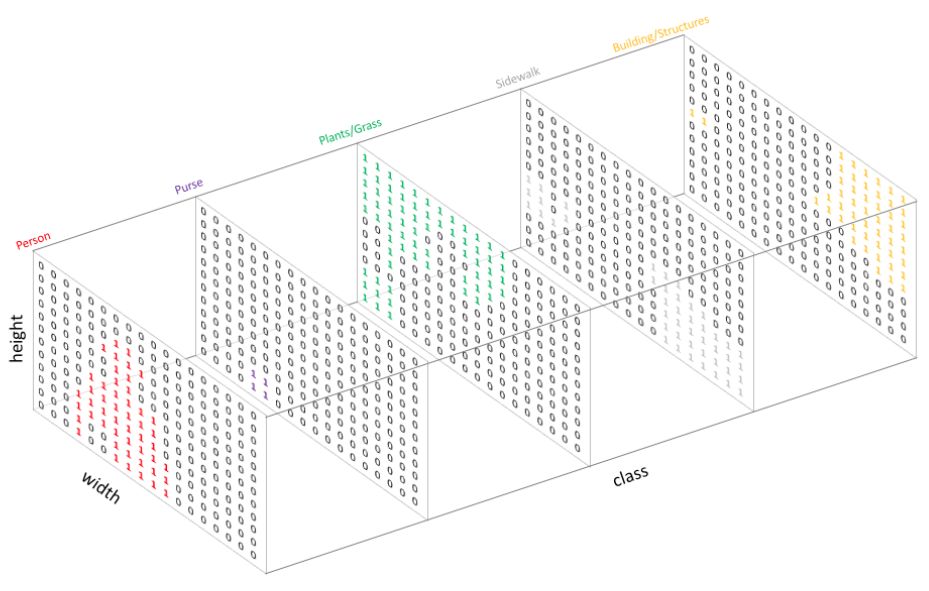
В примере этот тензор заполнен нулями и единицами, но в общем случае там будут стоять рейтинги классов, принимающие произвольные значения. К этим рейтингам в каждой пространственной позиции применяется операция SoftMax, чтобы перевести их в вероятности и настраивать нейросеть, мак�симизируя логарифмы правдоподобия для каждого изображения в каждом пикселе:
где
-
- номер изображения в мини-батче, состоящем из изображений;
-
- ширина и высота каждого изображения;
-
- число классов;
-
- параметры сети.
Это эквивалентно минимизации попиксельных кросс-энтропийных потерь.