Усложнения рекуррентных сетей
На базе рекуррентной нейронной сети можно строить более сложные нейросетевые архитектуры, обладающие большей выразительной силой. Опишем основные подходы.
Многослойные сети
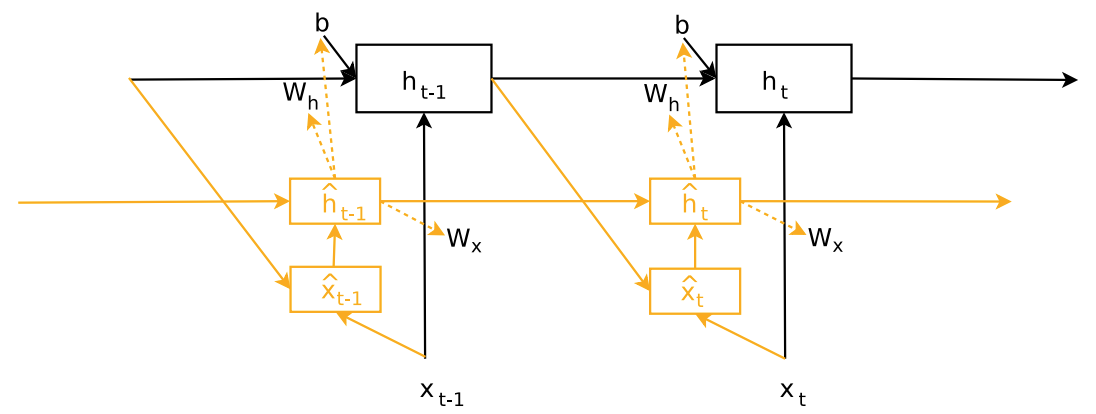
Точно так же, как для получения более высокоуровневых признаков изображений мы наслаивали несколько свёрточных слоёв, можно наслаивать несколько рекуррентных сетей друг поверх друга, как показано на рисунке:
Каждый ярус отвечает рекуррентной сети со своими параметрами. При этом рекуррентная сеть более высокого яруса принимает на вход выходы рекуррентной сети нижестоящего яруса в соответствующий момент времени.
Эта схема позволяет извлекать более сложные зависимости, основанные на нескольких нелинейных преобразованиях, и называется многослойной рекуррентной сетью (multilayer RNN, stacked RNN) [1].
Комбинация низкоуровневых и высокоуровневых признаков
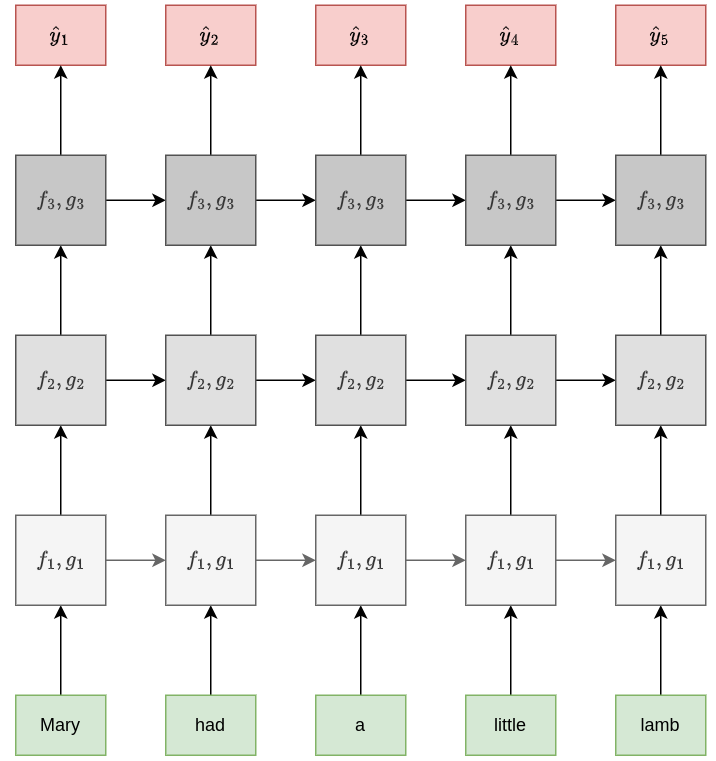
В многослойной рекуррентной сети можно добавлять тождественные преобразования (identity connections) с более низких ярусов рекуррентной сети сразу на более высокие, минуя промежуточную обработку. Тогда входы вышестоящей рекуррентной сети будут состоять одновременно из выходов нескольких нижестоящих рекуррентных блоков.
Это облегчает настройку сети методом обратного распространения ошибки (улучшает распространение градиентов) и позволяет сети верхнего яруса моделировать более сложные зависимости, комбинируя как высокоуровневые, так и низкоуровневые признаки.
Схема архитектуры:
С этим подходом мы уже сталки�вались в модели DenseNet при обработке изображений.
Сlockwork RNN
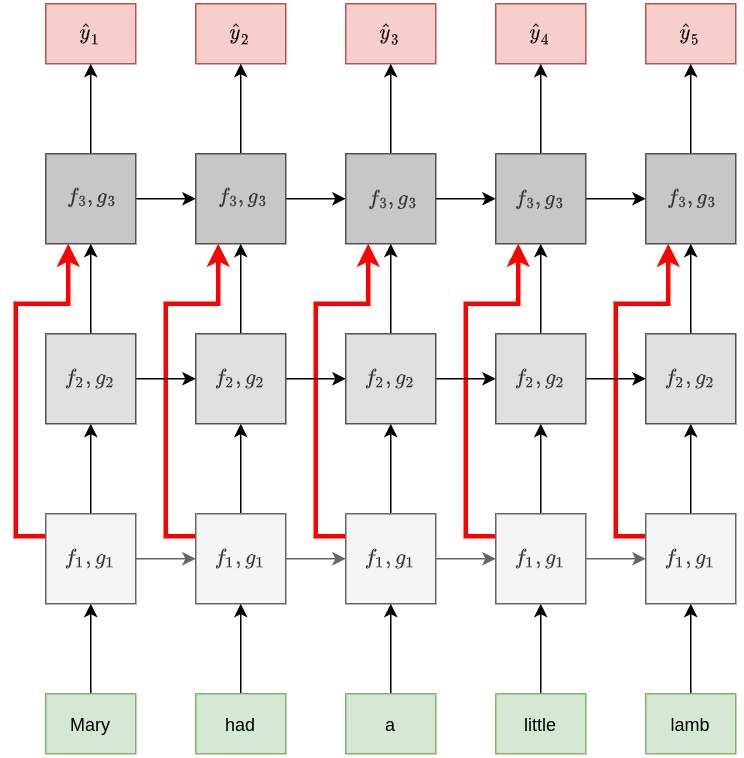
Подход clockwork RNN [2] позволяет обрабатывать последовательности в разных временных масштабах. Основная идея состоит в том, что рекуррентные блоки разных ярусов многослойной рекуррентной сети (stacked RNN) обновляются с различной частотой, что позволяет модели лучше помнить историю и эффективно обобщать информацию о длинных входных последовательностях.
Ниже приведён пример такой архитектуры:
В случае обработки текстов нижние слои сети могут обрабатывать текст на уровне слов, средние - на уровне предложений, а более высокие - на уровне параграфов, обобщая основные мысли текста в целом.
Двунаправленная сеть
Часто строится прогноз для каждого элемента последовательности, когда вся последовательность известна заранее.
Например, при разборе слов предложения на части речи мы знаем всё предложение от начала и до конца.
Это позволяет строить более точные прогнозы, которые учитывают как левый, так и правый контекст каждого элемента последовательности.
Для этого используется архитектура двунаправленной рекуррентной сети (bidirectional RNN, [3]), состоящей из двух независимых рекуррентных сетей:
-
первая сеть обрабатывает элементы последовательности слева-направо;
-
вторая - справа-налево.
Первая сеть кодирует входы состояниями , вторая - состояниями ,
Далее для каждого момента времени состояния обеих рекуррентных сетей конкатенируются в один вектор, кодирующий как левый, так и правый контекст:
Это объединённое состояние подаётся в качестве входа в вышестоящую сеть для последующей обработки:
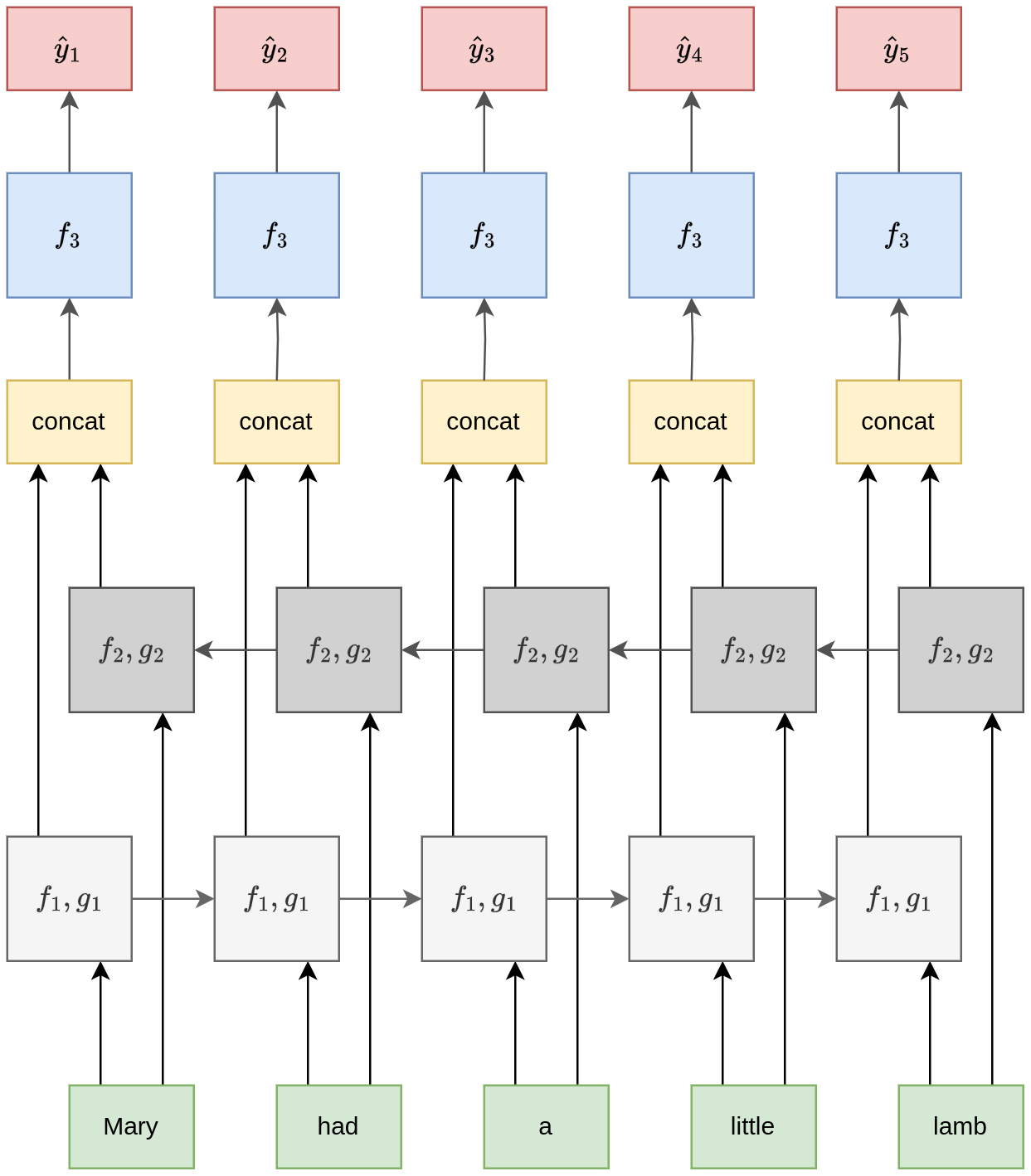
У этого подхода возможны вариации:
-
Верхняя сеть тоже может быть рекуррентной.
-
Вместо скрытых состояний рекуррентных сетей можно использовать их выходы.
-
Перед подачей на вход конкатенацию состояний можно преобразовать линейным слоем, чтобы снизить её размерность:
Обратим внимание, что при настройке двунаправленной сети градиенты будут распространяться из каждой позиции как налево, так и направо, что усложняет настройку сети. Для длинных последовательностей нужно использовать обрезанную версию алгоритма BPTT в обе стороны (и в прошлое, и в будущее).
Динамическая сеть
В традиционной рекуррентной сети веса для пересчёта состояний на всех итерациях обработки одинаковы. В работе [4] предлагается сделать их динамическими, предсказывая эти веса дополнительной сетью, называемой гиперсетью (hypernetwork). Ранее мы уже изучали этот подход. Эта сеть реализует мягкую, а не жёсткую общность весов (soft weight sharing) через общность параметров гиперсети. Такая схема позволяет более гибко обрабатывать последовательности разных типов, приспосабливая под них параметры основной рекуррентной сети, выдающей итоговые результаты.
Эта схема показана на рисунке [4]: