Механизм внимания в рекуррентных сетях
Рекуррентные нейронные сети призваны обрабатывать входные данные в виде последовательности элементов произвольной длины. Центральная задача при обработке таких данных - это полноценный учёт исторических элементов последовательности, которые нейросеть уже пронаблюдала.
Базовая модель Элмана способна обрабатывать лишь короткие последовательности, поскольку обращение к более ранней истории наблюдений связано с многократным перемножением матриц в архитектуре сети, из-за чего информация о давних наблюдениях теряется.
Рекуррентные сети, основанные на гейтах, такие как LSTM и GRU, позволяют лучше учитывать раннюю историю за счёт замены численно неустойчивых многократных перемножений матриц на взвешенные суммы, что позволяет помнить историю лучше и эффективнее учитывать её в прогнозах.
Однако даже эти модели не могут полноценно обработать слишком длинные последовательности, поскольку вынуждены хранить информацию о всех ранее виденных наблюдениях (которых может быть оче�нь много) в векторе скрытого состояния фиксированного размера.
Для более эффективной обработки длинных последовательностей в нейронных сетях используется механизм внимания (attention mechanism [1]), позволяющий на этапе генерации выхода обращаться к любому элементу входной последовательности напрямую, при котором потери информации не может быть в принципе!
Цена за подобное усовершенствование - повышенные расходы на память и вычисления, поскольку теперь при генерации каждого выхода сети приходится помнить всю входную последовательность и обращаться ко всем ранее виденным её элементам.
Далее мы разберём механизм внимания более подробно на примере рекуррентной сети для задачи машинного перевода. Те же самые принципы могут использоваться для обработки последовательностей любого типа.
Идея внимания
Рассмотрим задачу машинного перевода (machine translation), то есть автоматического перевода текста на с одного языка на другой. Эту задачу можно решить архитектурой many-to-many, используя две рекуррентные сети - кодировщик и декодировщик, как показано на схеме:
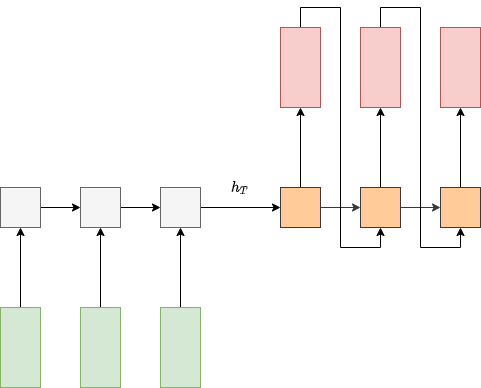
Кодировщик проходит по токенам входной последовательности (словам на исходном языке), после чего её итоговое внутреннее состояние кодирует всю эту последовательность целиком в виде вектора фиксированного размера .
Внутреннее состояние декодировщика инициализируется состоянием и осуществляет генерацию перевода в авторегрессионном режиме, при котором выход сети в предыдущий момент времени является входом в следующий момент времени.
Указанная архитектура обладает тем недостатком, что переводимый текст может быть произвольной длины, но конструктивно его приходится кодировать в виде вектора фиксированного размера , что приводит к потере информации о тексте, если он окажется слишком длинный (чем длиннее - тем больше потеря информации).
В статье [2] предложено использовать механизм внимания (attention mechanism), чтобы при генерации каждого выходного токена декодировщик мог смотреть на все токены входной последовательности, как показано на рисунке:
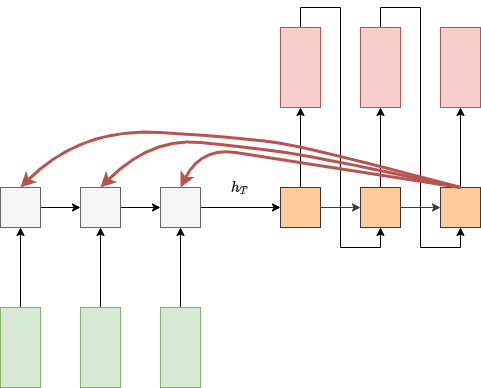
Так кодировочной сети не придётся запоминать каждый входной токен, и потери информации не произойдёт.
Заметим, что внимание нацелено на все входные токены, а не на какой-то один (soft attention). Это объясняется особенностями настройки нейросетей и позволяет повысить точность перевода, учитывая не только сами слова, но и контекст соседних слов, в котором они находятся.
Например, слово "замок" может быть переведено как "castle" или как "lock". Для разрешения неоднозначности необходимо анализировать соседние слова:
Замок имеет шесть башен и окружён глубоким рвом -> castle.
Замок заржавел, и ключ в нём не поворачивается -> lock.
В первом случае внимание восстановит смысл по таким словам, как "башня" и "ров". А во втором - по слову "ключ".
Технически механизм внимания использует три сущности:
-
запросы (queries);
-
ключи (keys);
-
значения (values).
Его работа вдохновлена SQL-запросами к базе данных вида
select VALUE where KEY=QUERY
в которых считывается значение записи (VALUE), у которой ключ (KEY) совпадает с запросом (QUERY).
Графически это можно представить следующим образом:
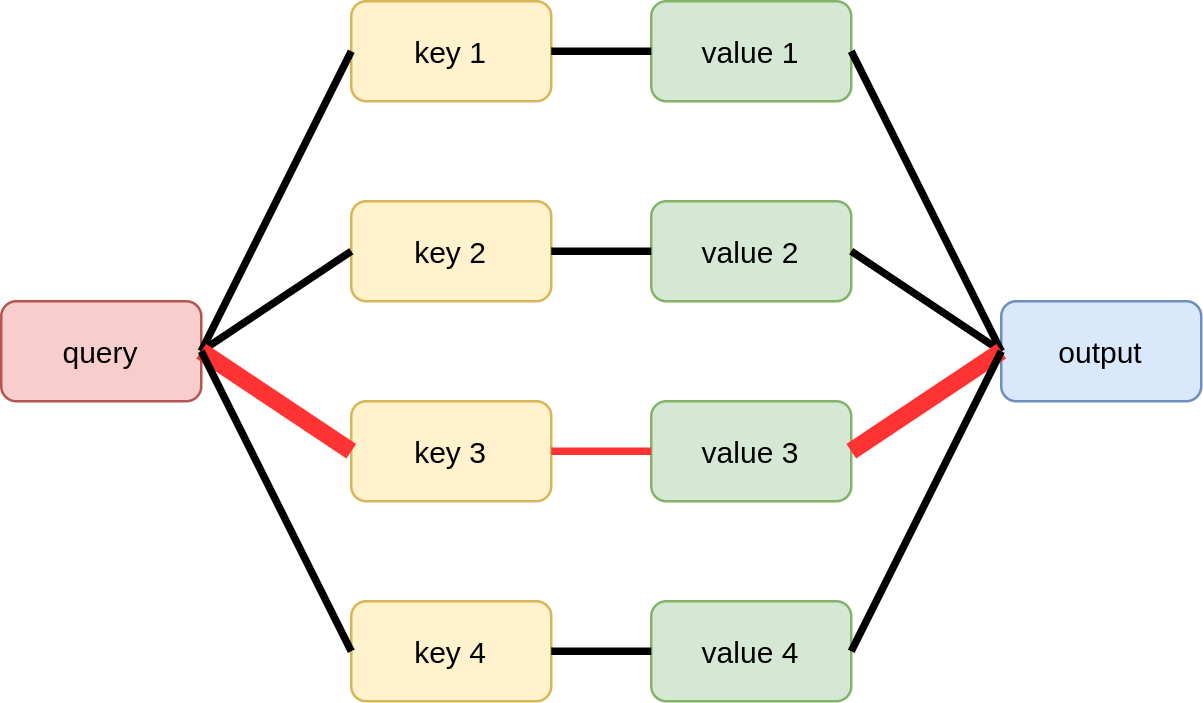
Реализовать подобный механизм напрямую в нейронных сетях нельзя, поскольку для их настройки необходимо использовать дифференцируемые преобразования, а функция, осуществляющая запрос, представляет собой дискретную операцию.
Поэтому в нейросетях используется сглаженный вариант мягкого внимания (soft attention), вычисляющий функцию сходства запроса с каждым ключом, а затем усредняющий все значения пропорционально этой функции сходства.
Это можно проиллюстрировать следующим образом, где толщина линий обозначает степень сходства запроса и ключей, а также веса, с которыми соответствующие значения потом агрегируются для получения итогового ответа:

Более конкретно, в работе [2] в качестве кодировщика использована двунаправленная рекуррентная сеть, сопоставляющая эмбеддингу каждо�го входного токена векторы двух внутренних состояний и для рекуррентных сетей, проходящих слева направо и справа налево. Эти состояния конкатенируются в один вектор:
представляющий собой эмбеддинг слова с учётом его левого и правого контекста, то есть в контексте всего входного текста. Эти эмбеддинги в [2] представляют собой одновременно и ключи, и значения для всех входных токенов.
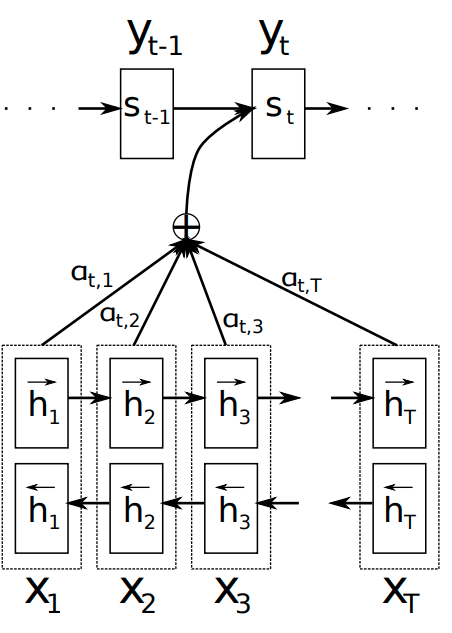
Декодировочная сеть представляет собой рекуррентную сеть, идущую слева направо и имеет внутреннее состояние , пересчитываемое с использованием механизма внимания. Запросом выступает текущее состояние декодировщика , а ключами и значениями - состояния кодировщика для всех элементов входной последовательности.
Генерация состояния декодировщика состоит из следующих этапов:
- Вычисляется степень соответствия каждого входного токена текущему состоянию, используя функцию score:
где - длина входного текста (число токенов).
- Вычисляются веса учёта состояний кодировочной сети. Для этого степени соответствия пропускаются через SoftMax-преобразование:
- Вычисляется контекстный вектор, объединяющий информацию об интересующих входных токенах в контексте текущего запроса:
- Осуществляется пересчёт состояния декодировочной сети, используя состояние, выход сети и контекстный вектор с предыдущего шага:
Графически это можно представить следующим образом [2]:
Как видим, рекуррентная сеть со вниманием имеет повышенные требования на память и вычисления по сравнению с обычной:
-
требуется хранить ключи и значения (внутренние состояния кодировщика)
-
при генерации каждого выходного токена нужно вычислять и учитывать контекстный вектор, причём сложность его вычисления пропорциональна длине всей входной последовательности.
Поэтому на практике длинную входную последовательность разбивают на отдельные блоки и обрабатывают их независимо. В машинном переводе естественно переводить не весь текст целиком, а каждое предложение по отдельности.
Вычисление соответствий
Вычислять соответствия между запросом и ключами можно по-разному. Ниже приведены основные варианты:
| английское название | формула |
|---|---|
| dot-product | |
| scaled dot-product | для |
| content-based | |
| additive | |
| multiplicative | |
| feed-forward |
Самым общим способом вычисления соответствия является применение многослойного персептрона (MLP) к запросу и ключу. Additive attention является частным случаем, когда используется всего один скрытый слой с активацией гиперболического тангенса.
Результат использования
Использование механизма внимания в [2] позволило значительно повысить качество машинного перевода, измеренное по мере BLEU, особенно для длинных текстов.
Ниже приведено среднее значение этой меры при обучении на предложениях длиной до 30 и до 50 слов
-
обычной many-to-many архитектурой (RNNenc)
-
many-to-many архитектурой с использованием внимания (RNNsearch) [2].
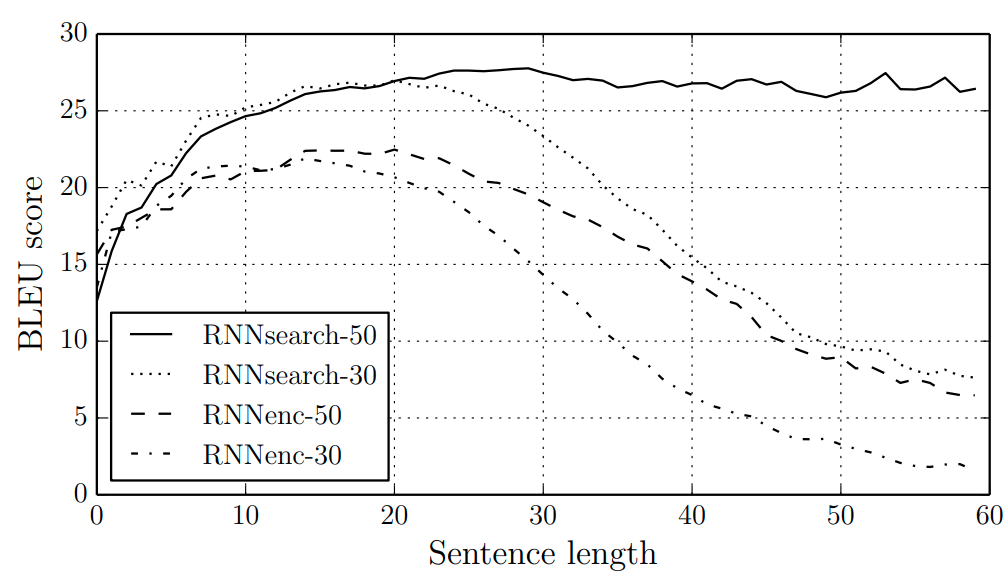
Чем BLEU выше, тем модель осуществляет более точный перевод. Как видим, нейросеть с механизмом внимания работает точнее обычной many-to-many архитектуры, а её качество тем выше, чем на более длинных предложениях она обучалась.
Интерпретируемость
Помимо повышения точности, другим важным преимуществом сети со вниманием является возможность интерпретации её работы за счёт визуализации весов внимания.
Это можно делать для каждого выходного токена , а можно визуализировать все веса сразу в виде матрицы внимания (attention matrix) , где
-
- длина входного предложения,
-
- длина выходного предложения (перевода),
а -й столбец содержит вектор вниманий при генерации -го выходного токена [1]:
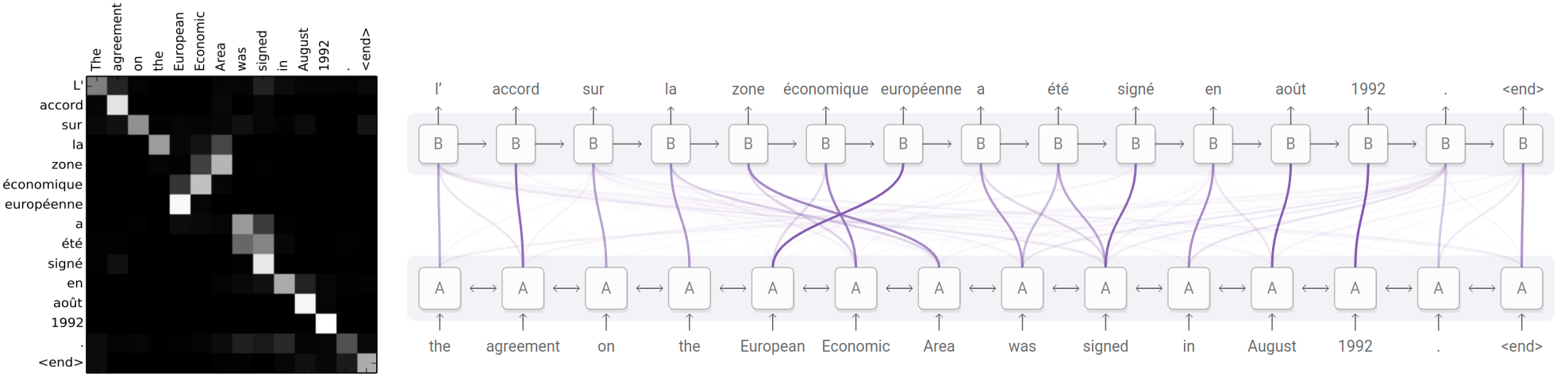
При корректно настроенном переводчике эта матрица будет близка к диагональной, поскольку последовательным входным словам обычно соответствуют последовательные выходные, за редкими исключениями, как в примере выше, когда "European Economic Area" по-французски переводится как "zone économique européen".
Другие применения
Предложенная архитектура со вниманием может эффективно использоваться и в других приложениях, таких как распознавание речи по спектрограмме (speech recognition) и текстовом описании изображений (image captioning), как показано на рисунке сверху и снизу [3]:

При распознавании речи о корректности настройки модели также можно судить по тому, насколько матрица внимания оказалась близка к диагональной, поскольку последовательным звукам должны соответствовать последовательно распознанные символы.
При описании изображений входом является не последовательность, а всё изображение целиком, представленное в виде промежуточного представления изображения внутри свёрточного кодировщика (например, на промежуточном слое сети VGG) . Запросами в механизме внимания выступает внутреннее состояние рекуррентной сети декодировщика, последовательно генерирующей слова. А ключами и значениями выступают преобразованные -мерные векторы внутреннего представления изображения. Поскольку для этих векторов известны их координаты, то можно определить, куда было нацелено внимание сети на изображении, когда декодировщик генерировал каждое слово. Если слово соответствует правильному объекту на изображении, как для слова frisbee выше, то это свидетельствует в пользу того, что нейросеть настроилась корректно и не переобучилась.