Жадный и лучевой поиск
Введение
Рассмотрим, ка�к можно улучшить качество текста, итеративно генерируемого слово за словом некоторой моделью, такой как рекуррентная сеть.
Предложенный метод имеет более широкую применимость. В частности, он может применяться:
к любым языковым моделям, например, трансформерам;
к генерации любых дискретных объектов (ДНК как последовательности нуклеотидов; сессии как последовательности действий пользователя на сайте и т.д.).
Сеть генерирует текст последовательно слово за словом среди уникальных слов словаря. На каждом шаге сеть выдаёт рейтингов каждого отде�льного слова (или символа при посимвольной генерации):
Эти рейтинги преобразуются в вероятности слов, используя SoftMax-преобразование:
При генерации последовательности можно перебирать все варианты следующего элемента последовательности, если число вариантов невелико. Если же их много, то число вариантов-кандидатов можно сужать за счёт выбора из случайного подмножества вариантов продолжения последовательности.
Случайная генерация
Варианты продолжения последовательности можно сэмлировать из SoftMax-распределения, предсказанного моделью, причём гиперпараметр температуры в SoftMax-преобразовании управляет контрастностью выходных вероятностей.
Как именно?
При сэмплирование по-прежнему сводится к выбору самого вероятного слова и генерирует текст, который будет максимально правильным, но слишком однообразным. Увеличение повышает разнообразие ценой уменьшения согласованности слов в тексте (или букв в случае посимвольной генерации).
Таким образом, стохастическая генерация последовательности слов (или других дискретных элементов) в рекуррентной сети происходит пошагово генерируя последовательно слово за словом:
-
,
-
,
-
,
-
и т. д.
На каждом шаге можно
-
выбирать один вариант (в жадном поиске всегда выбирается элемент с максимальной апостериорной вероятностью, но для большего разнообразия последовательности можно сэмплировать из распределения);
-
несколько вариантов, а далее выбирать среди них наилучший (реализуется в лучевом поиске, см. ниже).
Чтобы уменьшить риск генерации случайного слова, которое будет совсем выпадать из контекста, слова можно генерировать не из всего списка слов, а из подмножества максимально вероятных. Для этого есть два подхода:
-
Top-K sampling позволяет сэмплировать только слов, обладающих максимальной вероятностью.
-
Nucleus sampling: вместо задания задаётся пороговая вероятность . Слова генерируются не из всего списка, а из подмножества самых вероятных слов. Оно формируется следующим образом: слова сортируются по убыванию их вероятности, и в допустимое подмножество включается минимальное число топ-K самых вероятных слов так, что их суммарная вероятность стала выше . Таким образом, Nucleus sampling представляет собой разновидность top-K sampling с динамически изменяемым параметром K, ад�аптивно подстраиваемым под контекст.
Генерация слов продолжается, пока не будет сгенерирован специальный токен [EOS], означающий конец последовательности, либо пока вероятность окончания генерации (предсказываемая отдельным выходом сети) не превысит порог.
Нас интересует генерация последовательности слов, обладающая максимальным рейтингом, измеряющим качество всей сгенерированной последовательности.
Рейтинг последовательности
При генерации последовательности слов можно по-разному оценивать её качество. Например, использовать логарифм модельной вероятности сгенерированной цепочки:
Но такой способ будет поощрять более короткие последовательности, поскольку у них будет меньше вероятностей в произведении при расчёте рейтинга.
Чтобы простимулировать нейросеть генерировать более длинные варианты текста, рейтинг нормируют на длину выходной последовательности по формуле
где - гиперпараметр, управляющий предпочтительной длиной выходных последовательностей.
Как именно влияет на среднюю длину последовательностей?
При уменьшении рейтинг длинных последовательностей будет получаться выше, и они будут выбираться чаще.
В расчёт рейтинга также можно добавлять другие условия, измеряющие, насколько сгенерированный текст
-
разнообразен (содержит много уникальных n-грамм);
-
естественен (содержит длинные последовательности слов, которые реально встречаются в текстах).
Далее мы рассмотрим генерацию и поиск наилучшей последовательности по рейтингу. Вначале рассмотрим генерацию текста простым алгоритмом жадного поиска (greedy search), а затем опишем работу более продвинутого лучевого поиска (beam search), который осуществляет более полный перебор последовательностей и в результате находит последовательности с более высоким рейтингом.
Алгоритм жадного поиска
Простейший подход генерации слов или символов текста - генерировать каждый раз следующее слово или символ, приводящей к увеличенной последовательности с локально наивысшим рейтингом. Этот подход называется жадным поиском (greedy search).
Пример работы
Пусть, для простоты, генерация происходит не на уровне слов, а на уровне букв, причем рассматриваются только две буквы: "A" и "M". Будем рассматривать оба варианта продолжения последовательностей - и буквой "A", и буквой "М" (если бы число вариантов было большим, можно было бы рассматривать случайное подмножество максимально вероятных вариантов). Нам нужно сгенерировать слово из четырёх букв словаря, обладающего максимальным рейтингом :
В качестве рейтинга используется некоторое преобразование от модельной вероятности пронаблюдать именно такую цепочку символов в последовательности:
Процесс итеративного построения слова можно представить в виде дерева, каждый узел которого отвечает некоторому варианту выбранного слова с приписанным ему рейтингом.
Нулевой ярус дерева отвечает пустому слову, первый - слову из одной буквы ("A" или "M"), следующий - слову из двух букв ("AA", "AM", "MA", "MM") и т. д.
Поскольку нужно составить наилучшее слово из четырёх букв, нам требуется найти узел четвёртого яруса дерева, обладающий максимальным рейтингом.
Ниже представлен пример дерева выбора с рейтингами узлов:
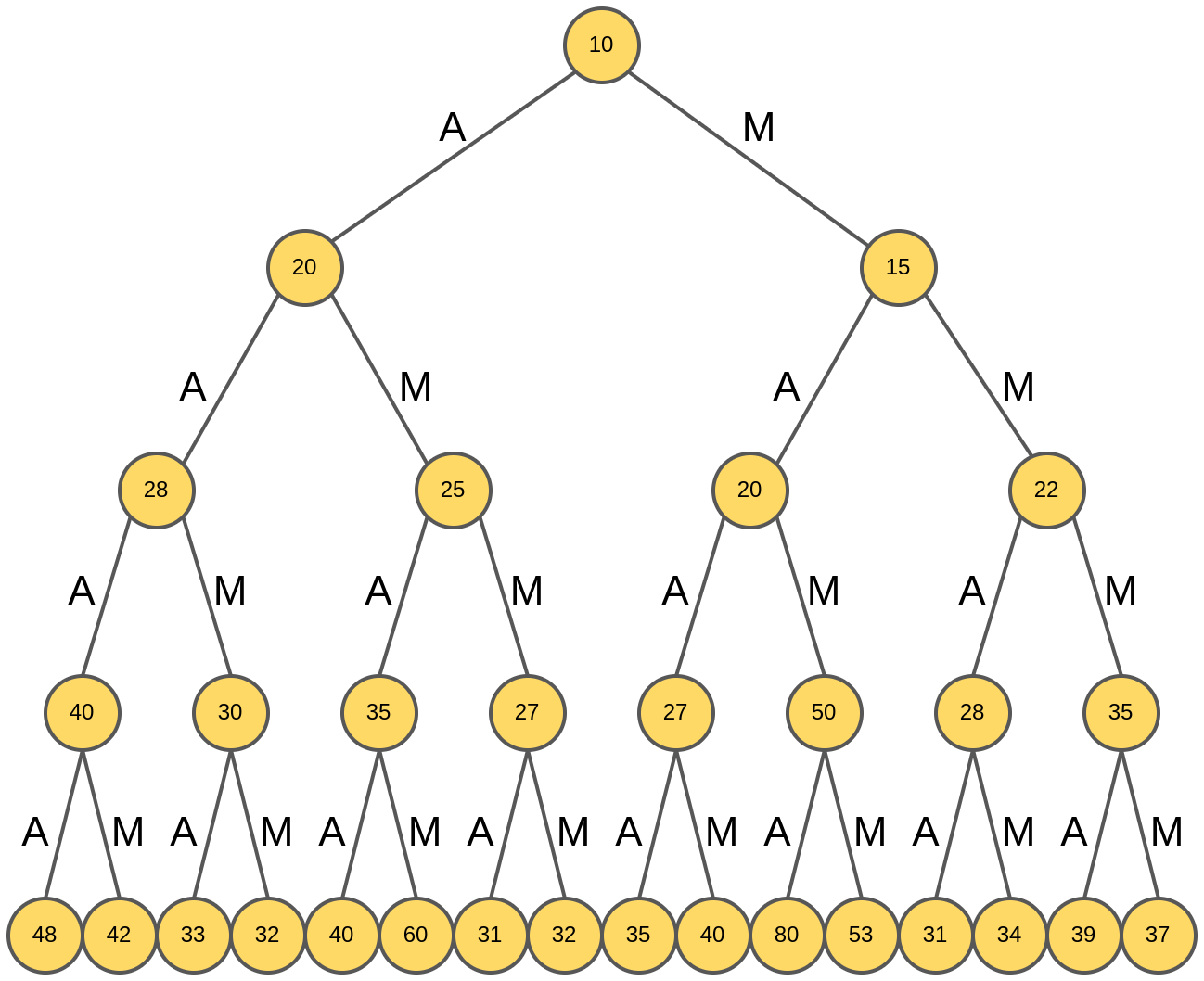
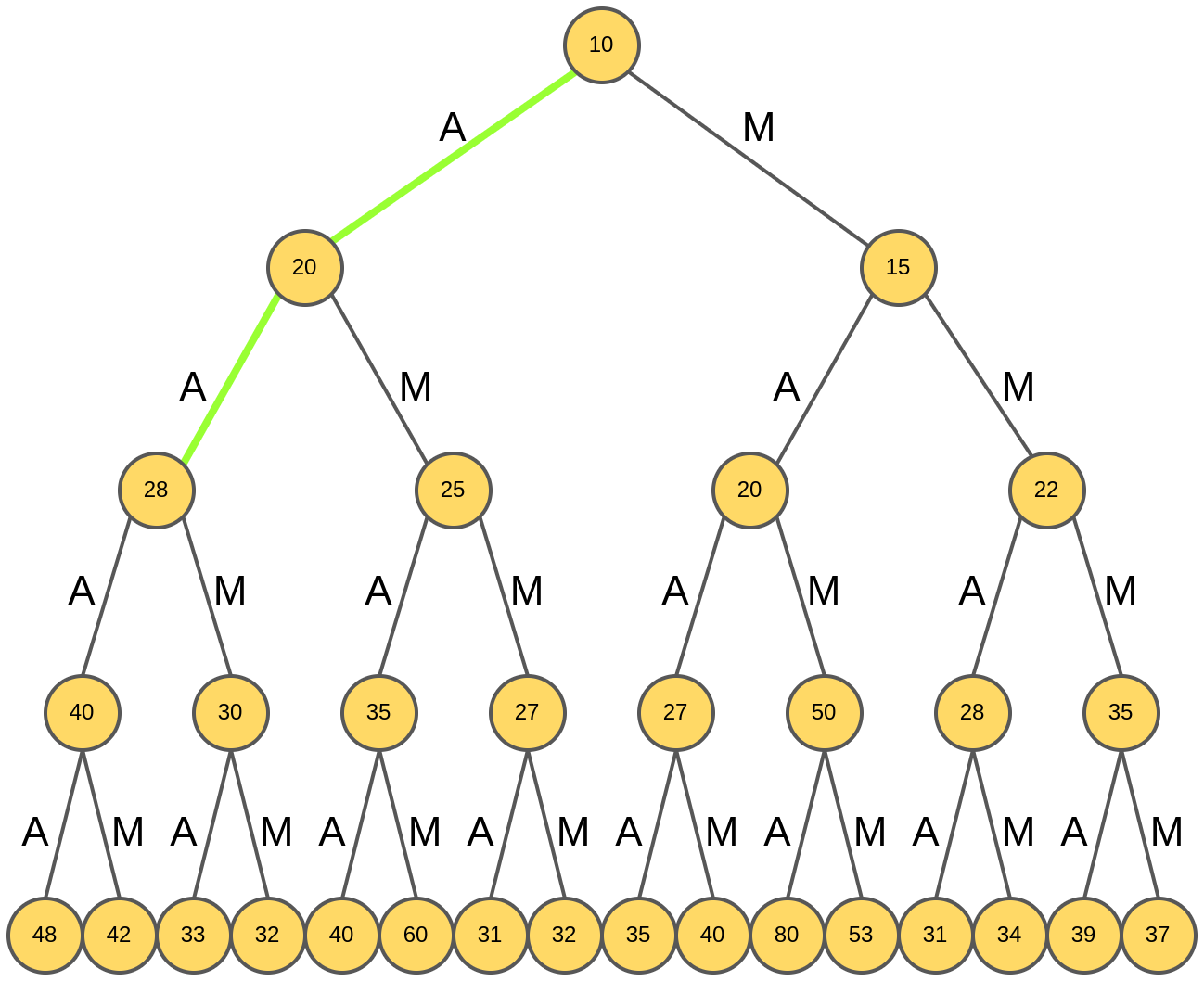
Генерация жадного поиска стартует из корня дерева (отвечающего пустому слову), и анализируются рейтинги слов из одной буквы:
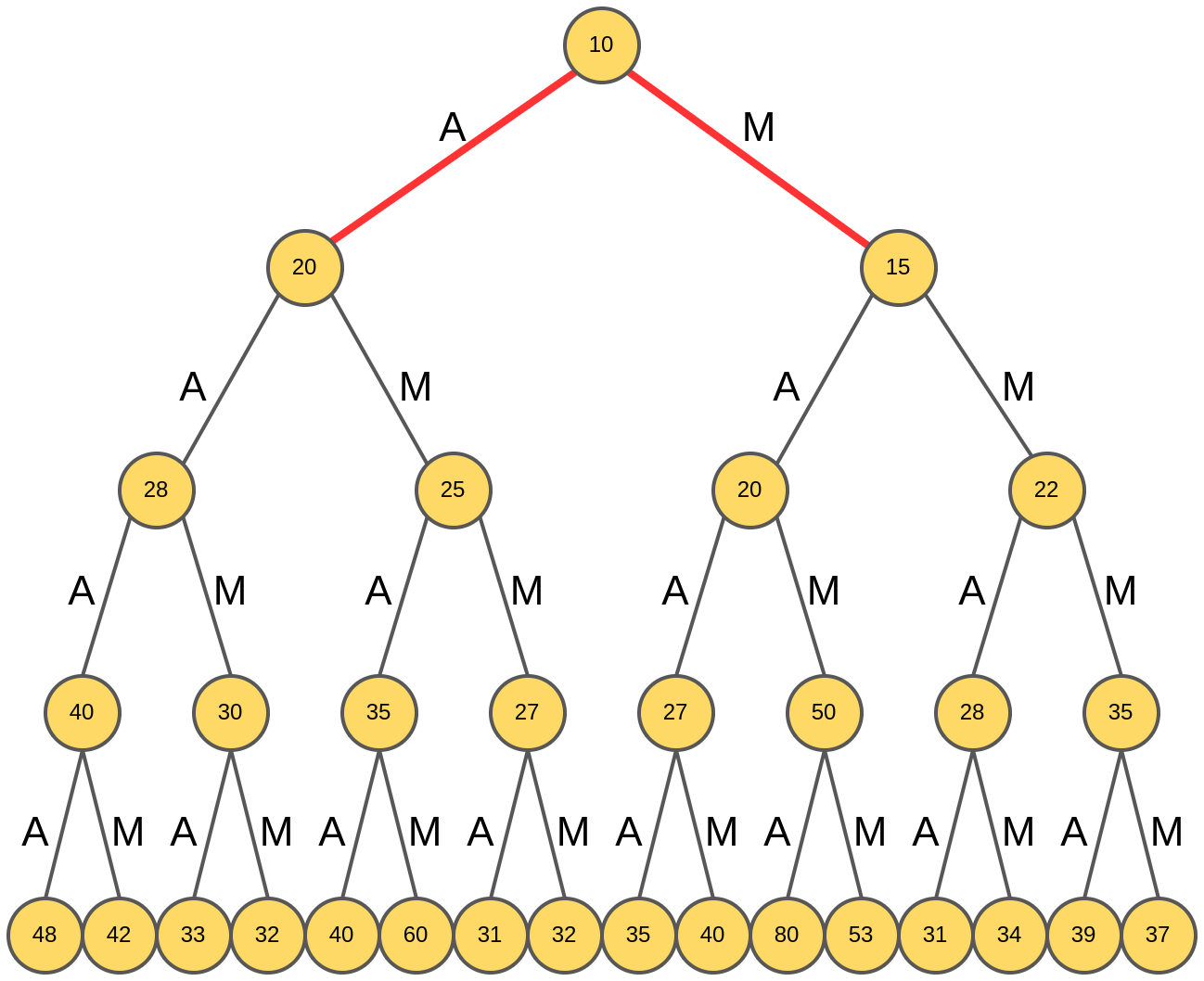
Выбирается слово "A", обладающее максимальным рейтингом 20.
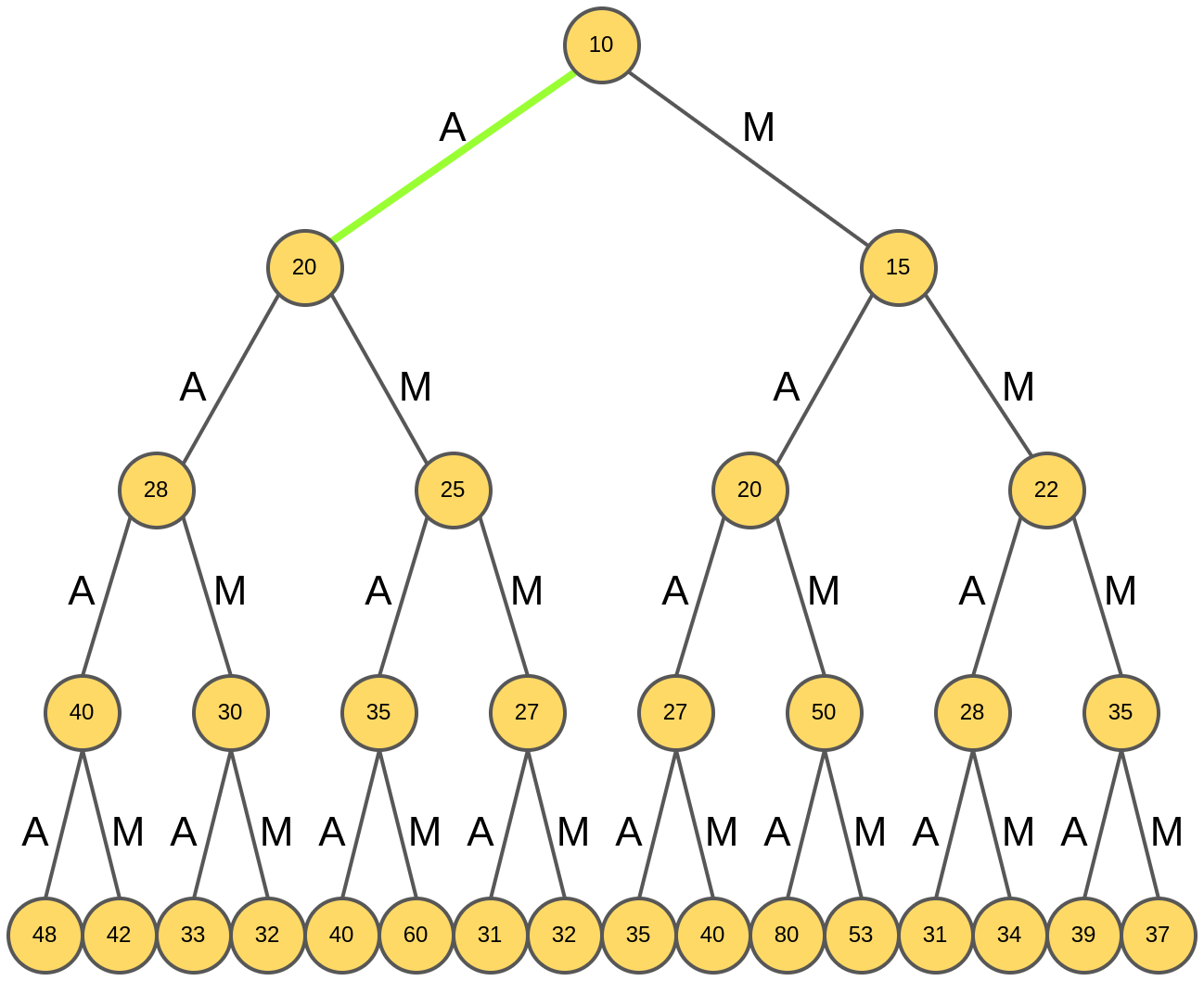
Далее для префикса "А" анализируются продолжения "AA" и "AM".
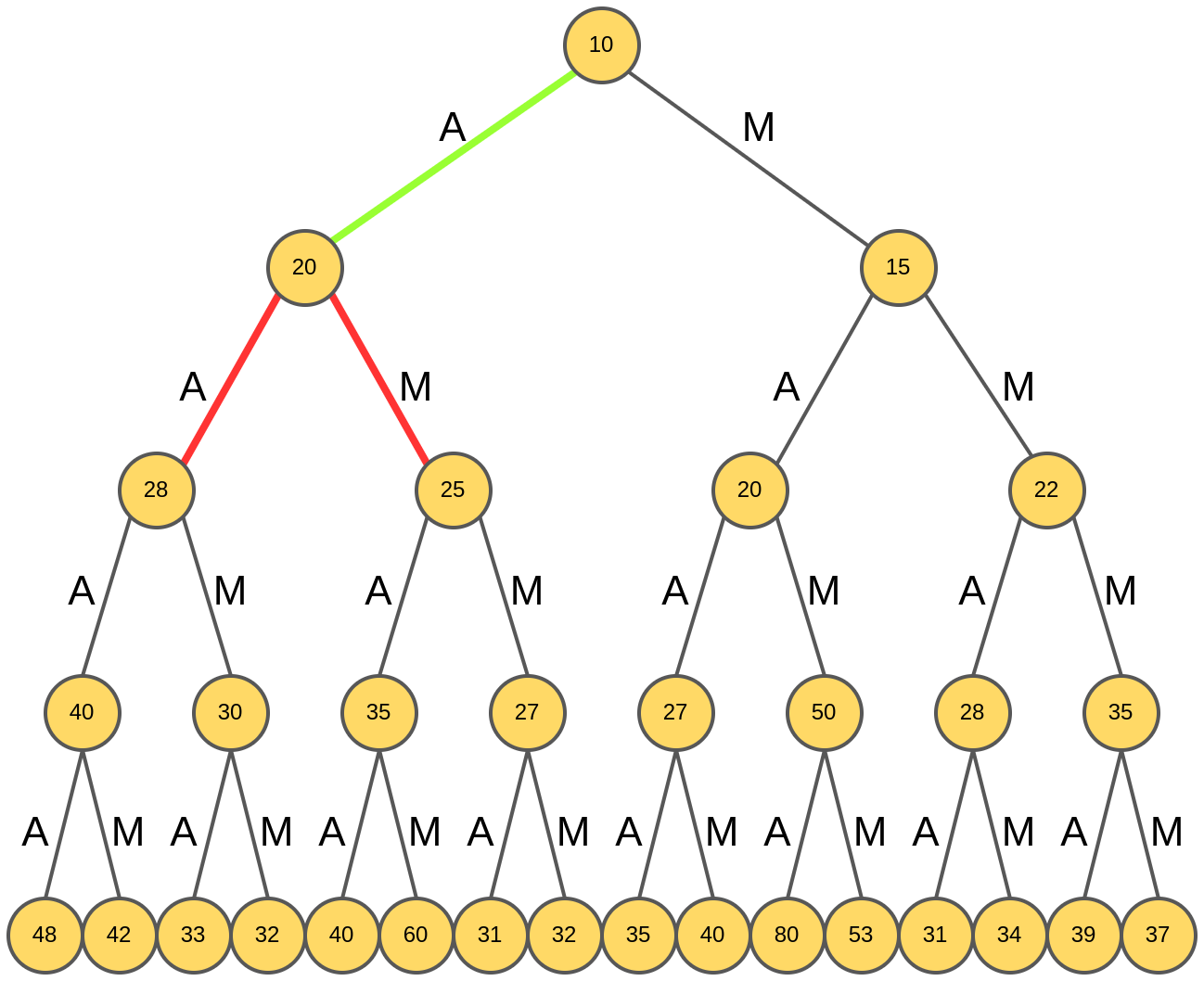
Выбирается "AM", обладающее максимальным рейтингом.
Далее снова анализируются возможные продолжения "AA": "AAA" и "AAM":
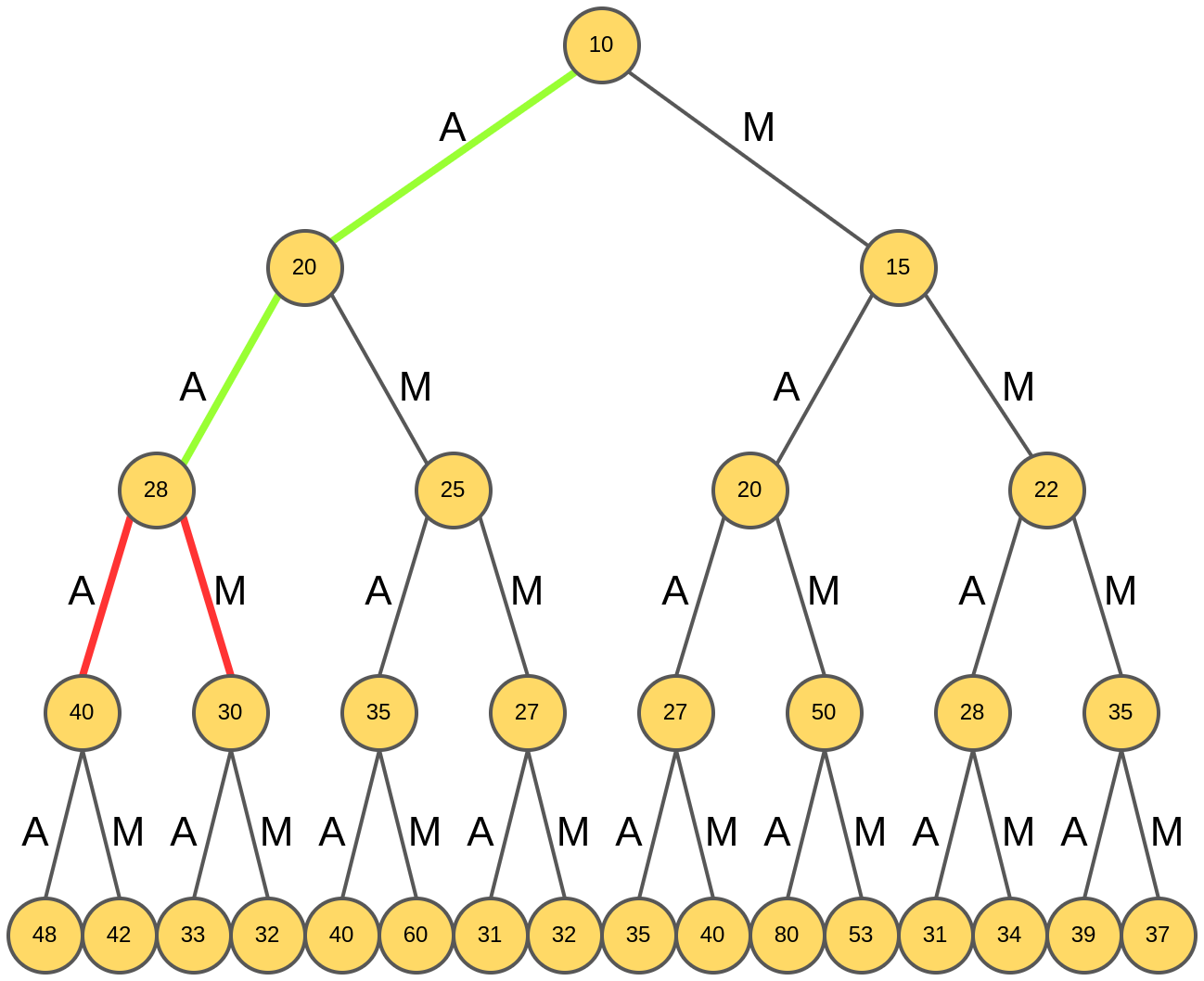
Выбирается префикс "AAA":
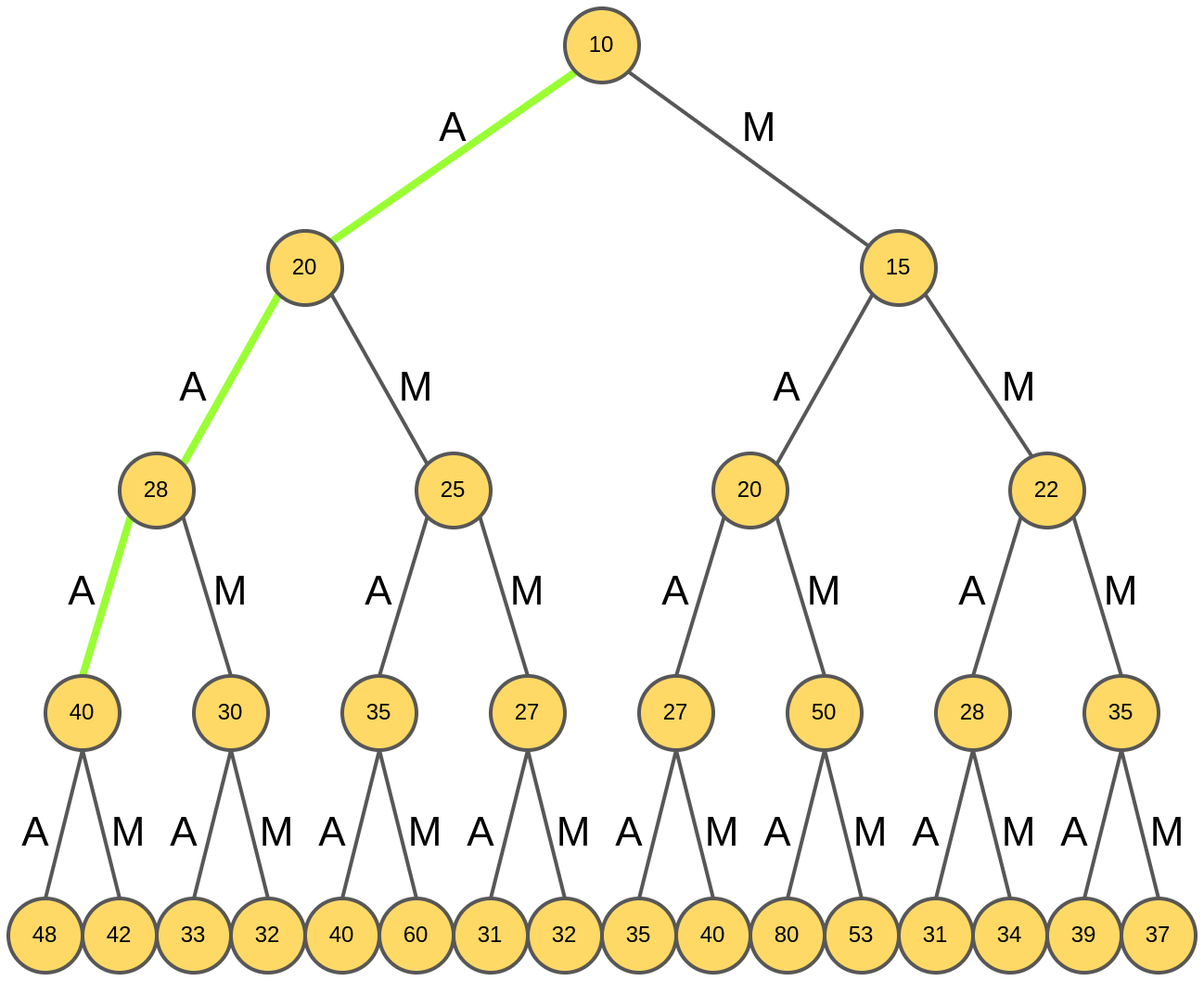
Для "AAA" снова анализируются продолжения: "AAAA" и "AAAM":
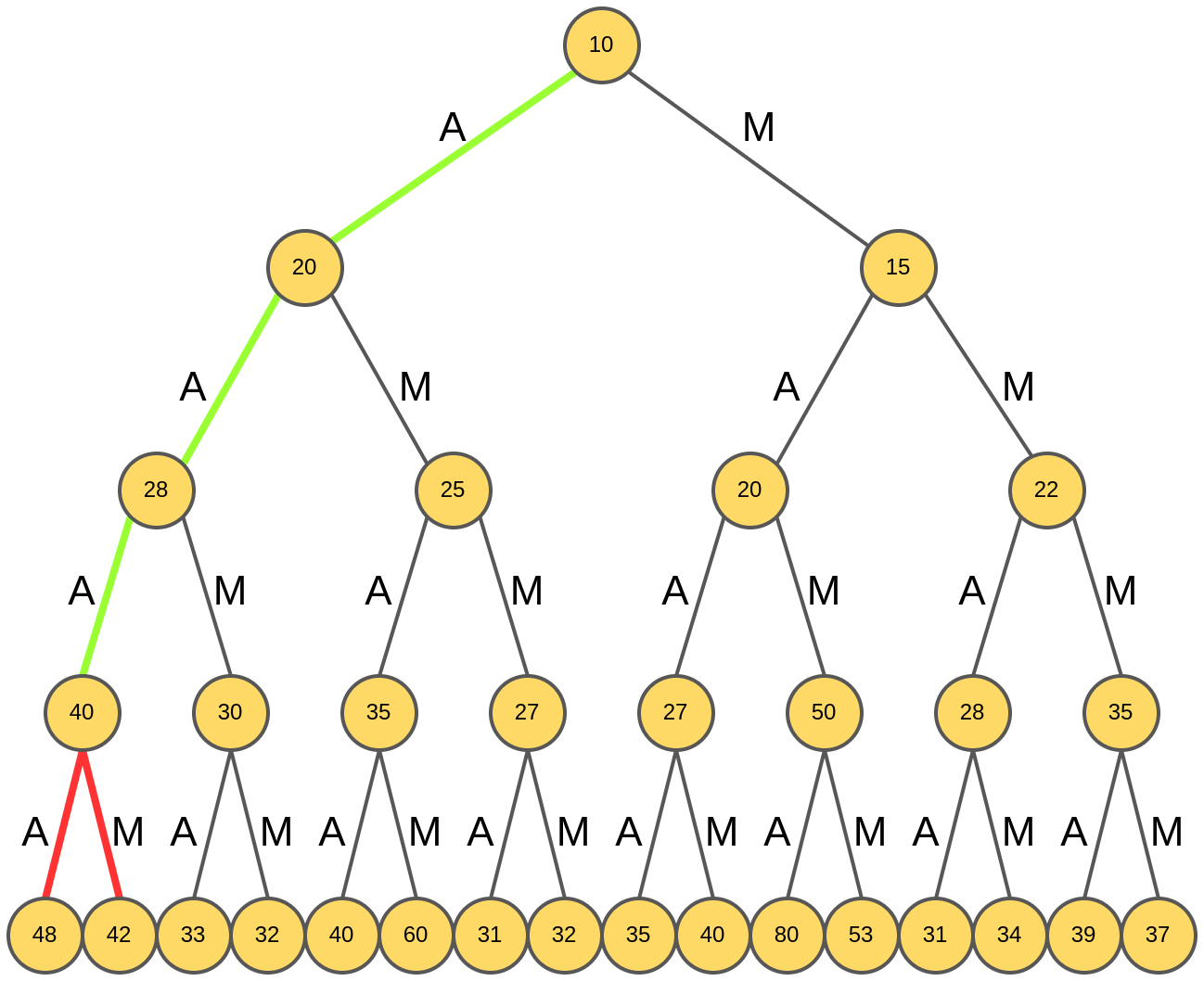
Выбирается слово "AAAA", и на этом генерация четырёхбуквенного слова завершается:
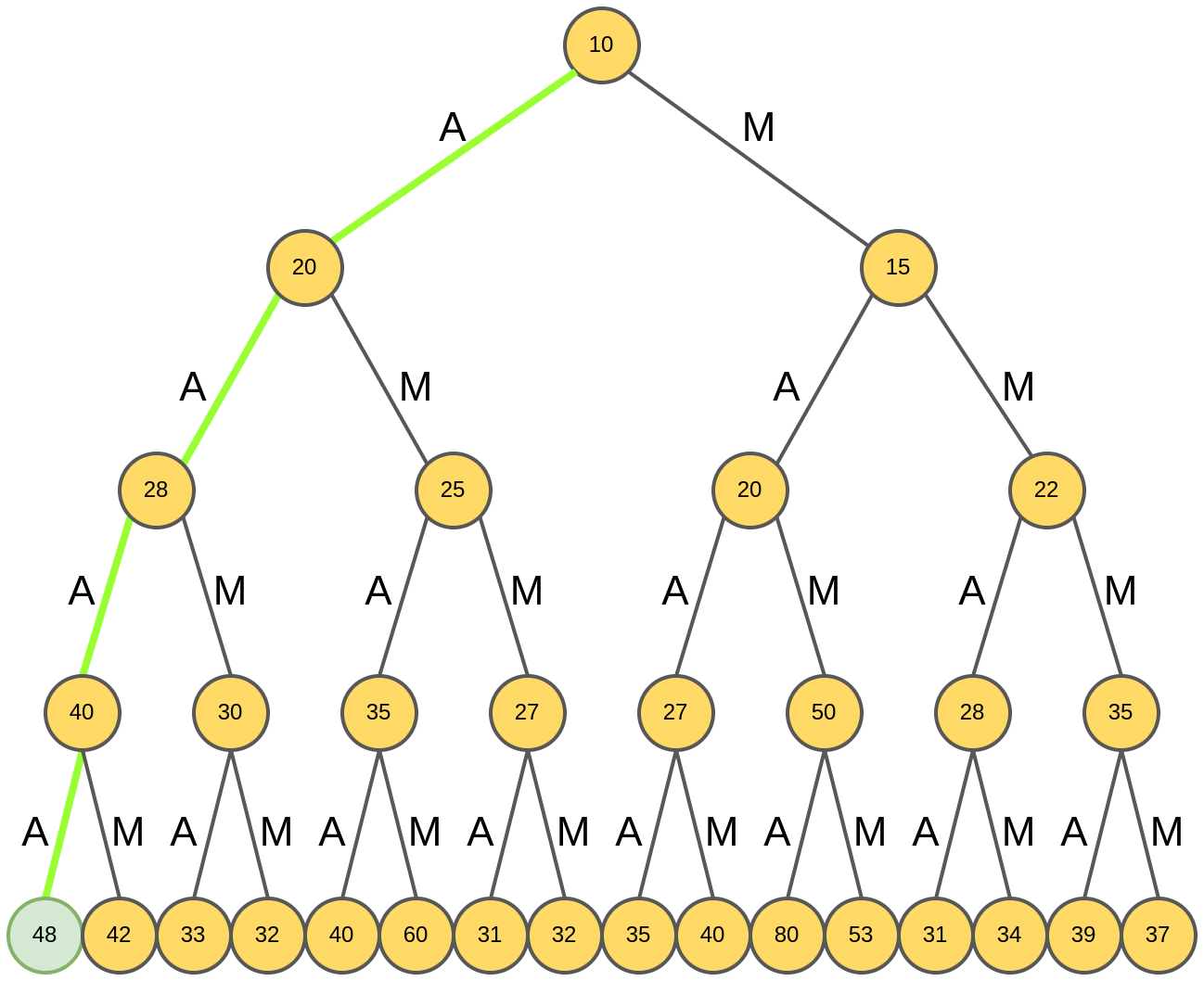
Полученное слово "AAAA" обладает рейтингом 48.
Алгоритм лучевого поиска
Поскольку каждый раз алгоритм смотрит только на один шаг вперёд, то сгенерированная последовательность может оказаться неоптимальной как целое, то есть обладающей недостаточно высоким рейтингом по сравнению с альтернативными вариантами последовательности.
Для повышения качества используется лучевой поиск (beam search [1], предложен в [2]), суть которого состоит в том, что выбирается каждый раз не одна гипотеза, а поддерживается набор из K лучших гипотез, где - гиперпараметр метода. Получив итоговых последовательностей, можно среди них выбрать ту, которая обладает максимальным рейтингом, что обеспечит более полный перебор вариантов.
Пример работы
Опишем алгоритм визуально для примера выше (генерация четырёхбуквенного слова из букв "A" и "M"), когда , т.е. параллельно дорабатываются две лучших гипотезы.
Генерация лучевого поиска стартует из корня дерева (отвечающего пустому слову) и анализируются рейтинги слов из одной буквы:
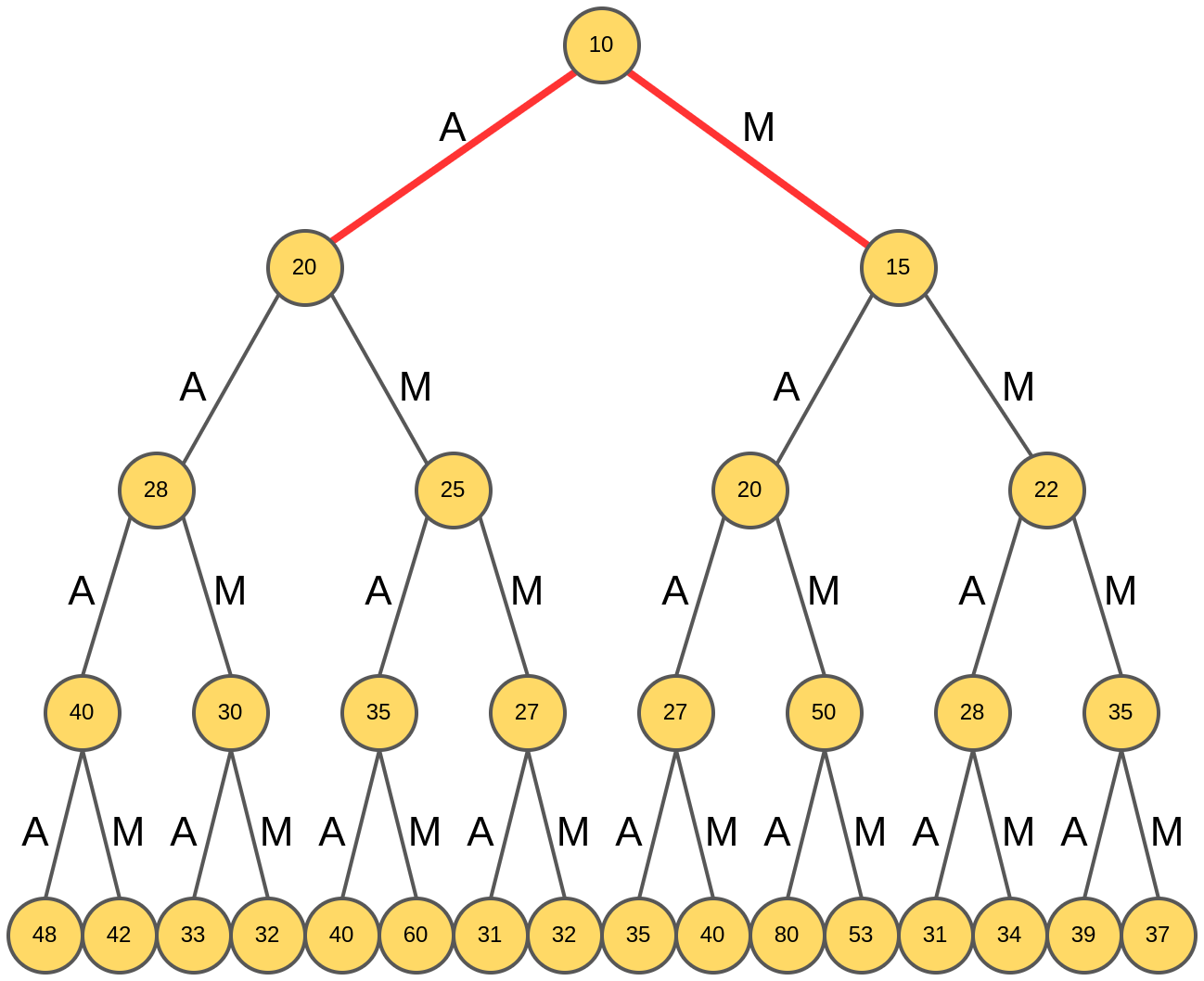
В отличие от жадного поиска, лучевой поиск идёт одновременно по двум маршрутам, используя гипотезы "A" и "M":
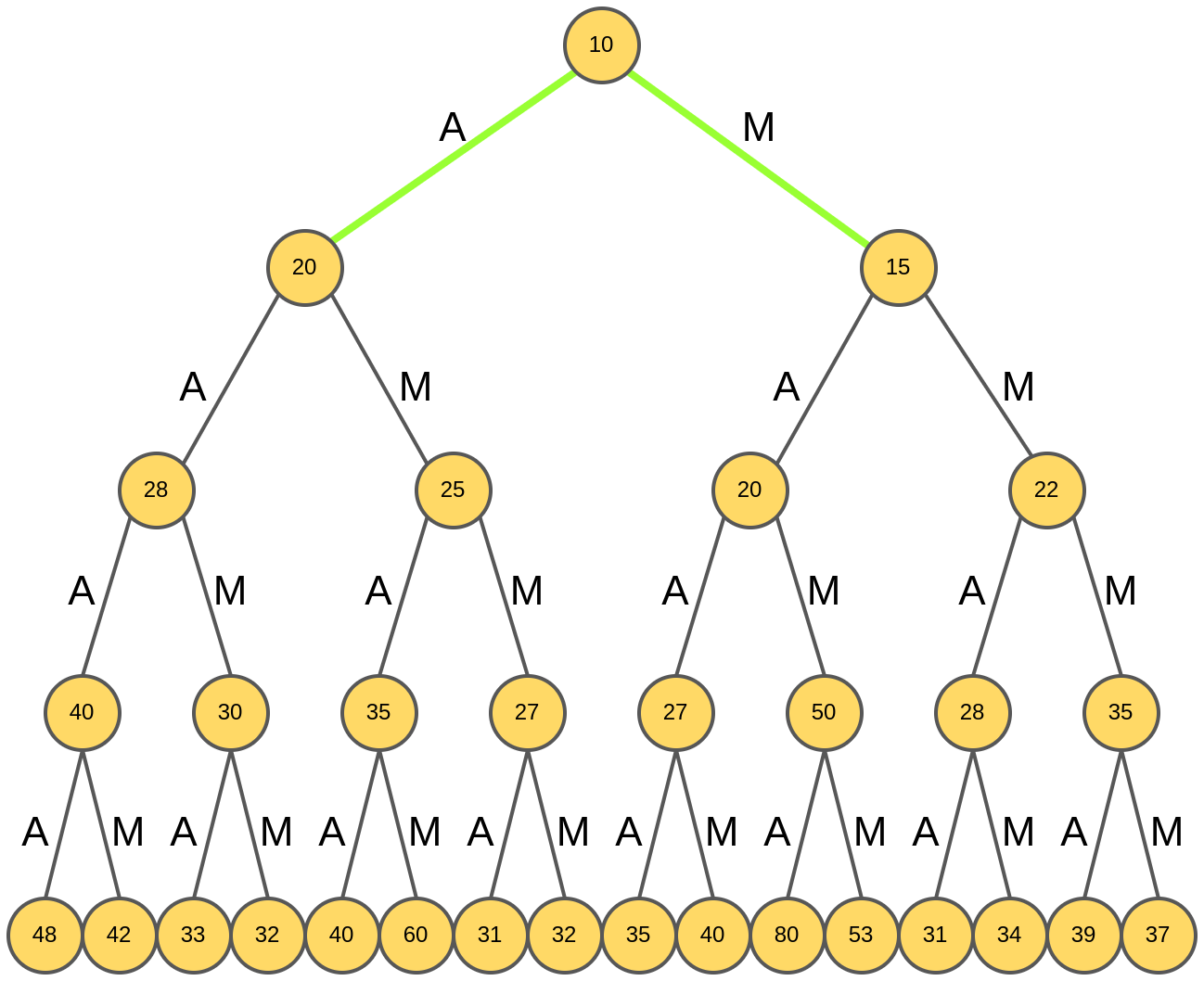
Для каждой гипотезы анализируются их всевозможные расширения:
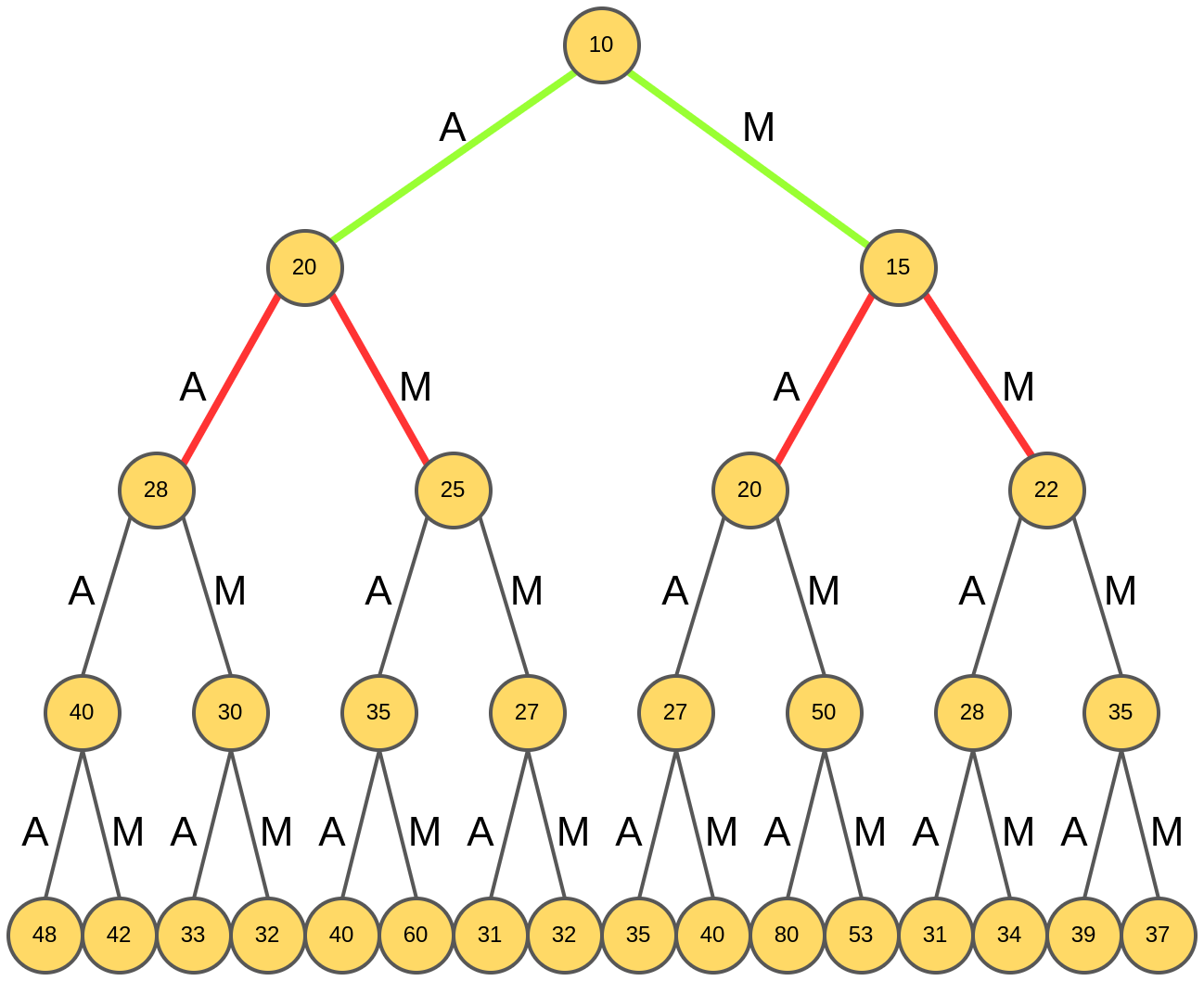
Наилучшими оказались гипотезы "AA" и "AM", префикс "M" отбрасывается как обеспечивающий расширение с меньшим рейтингом:
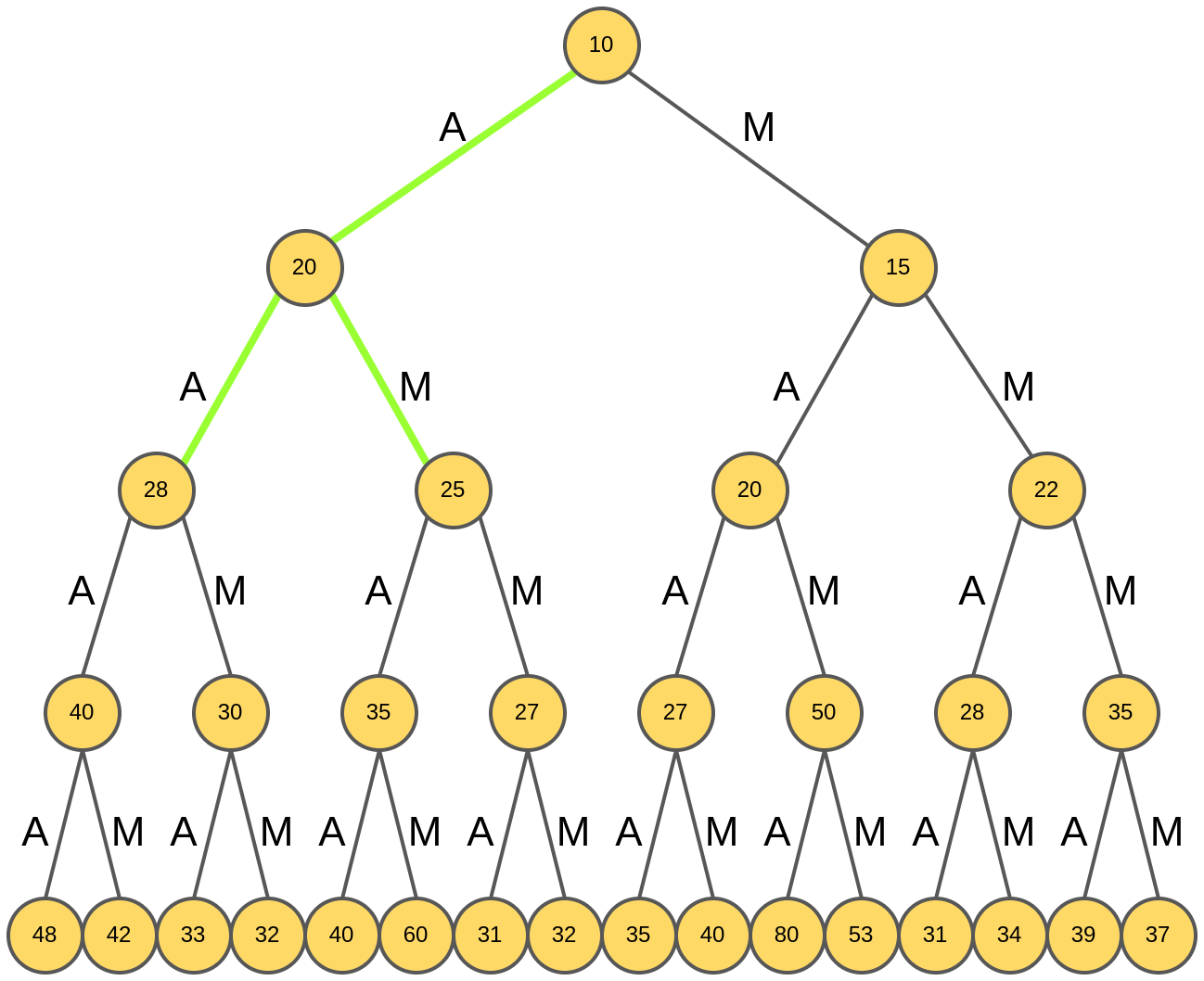
Снова анализируются продолжения каждой из двух гипотез:
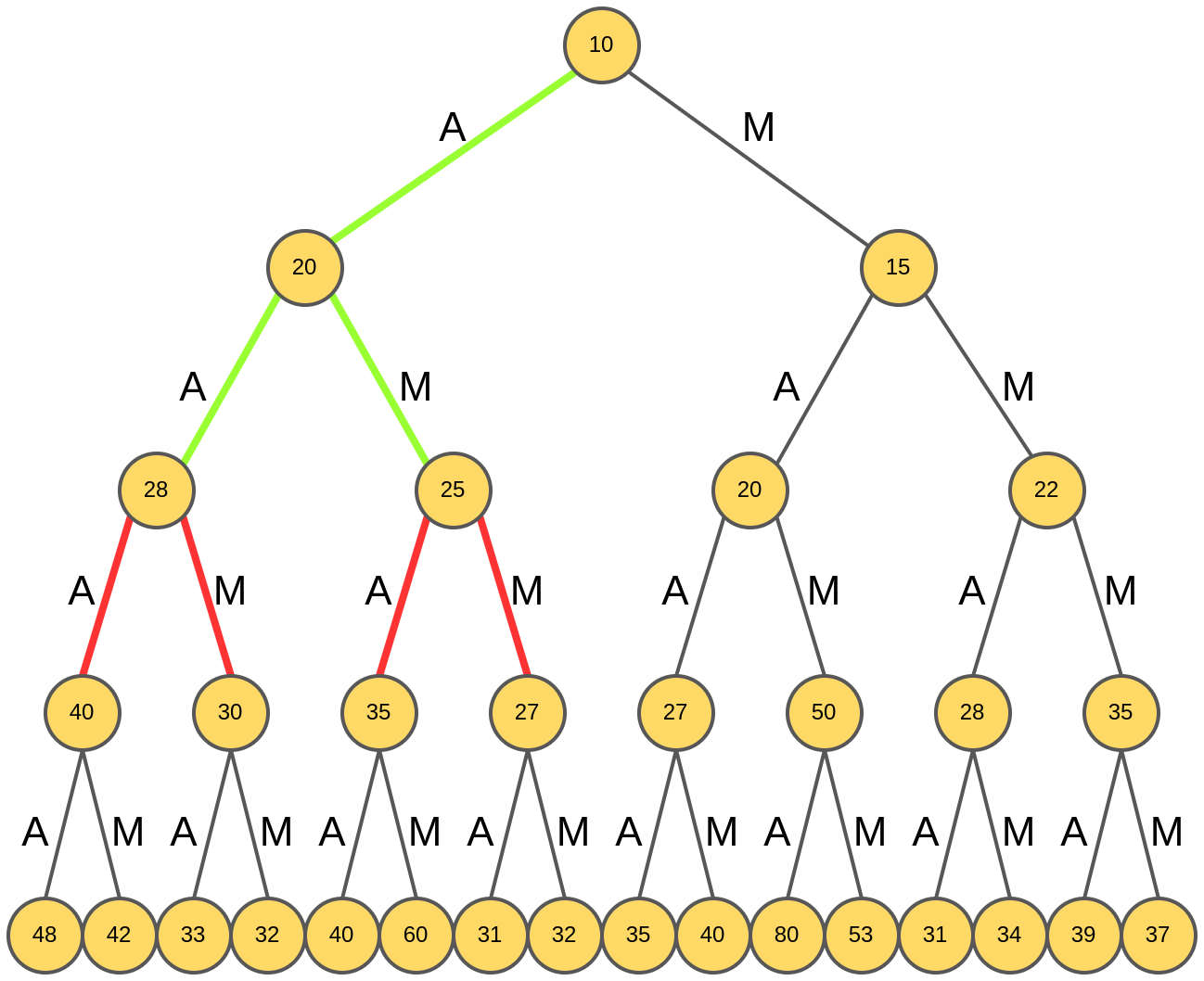
Лучшими продолжениями оказываются "AAA" и "AMA":
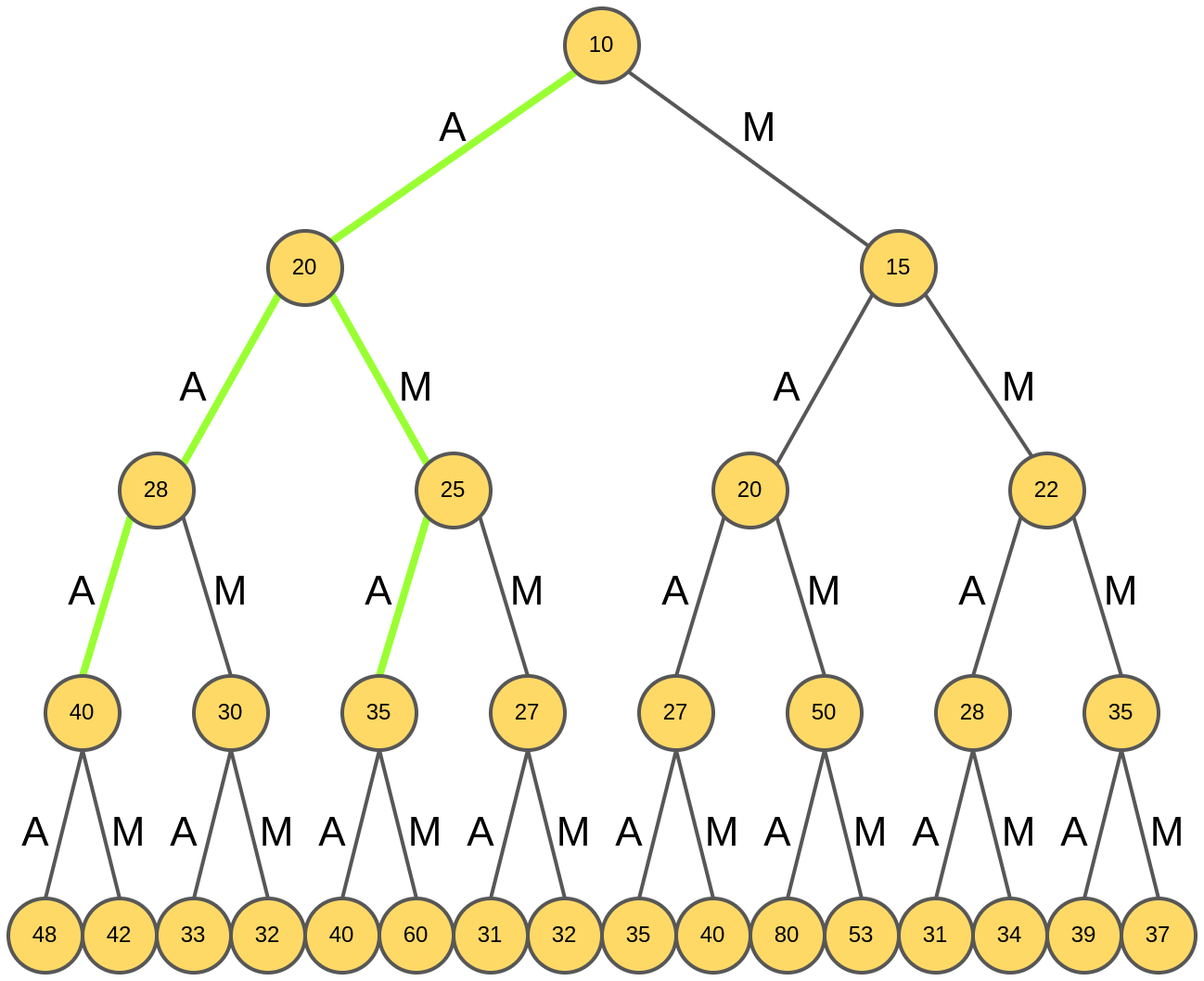
Анализируются продолжения этих гипотез:
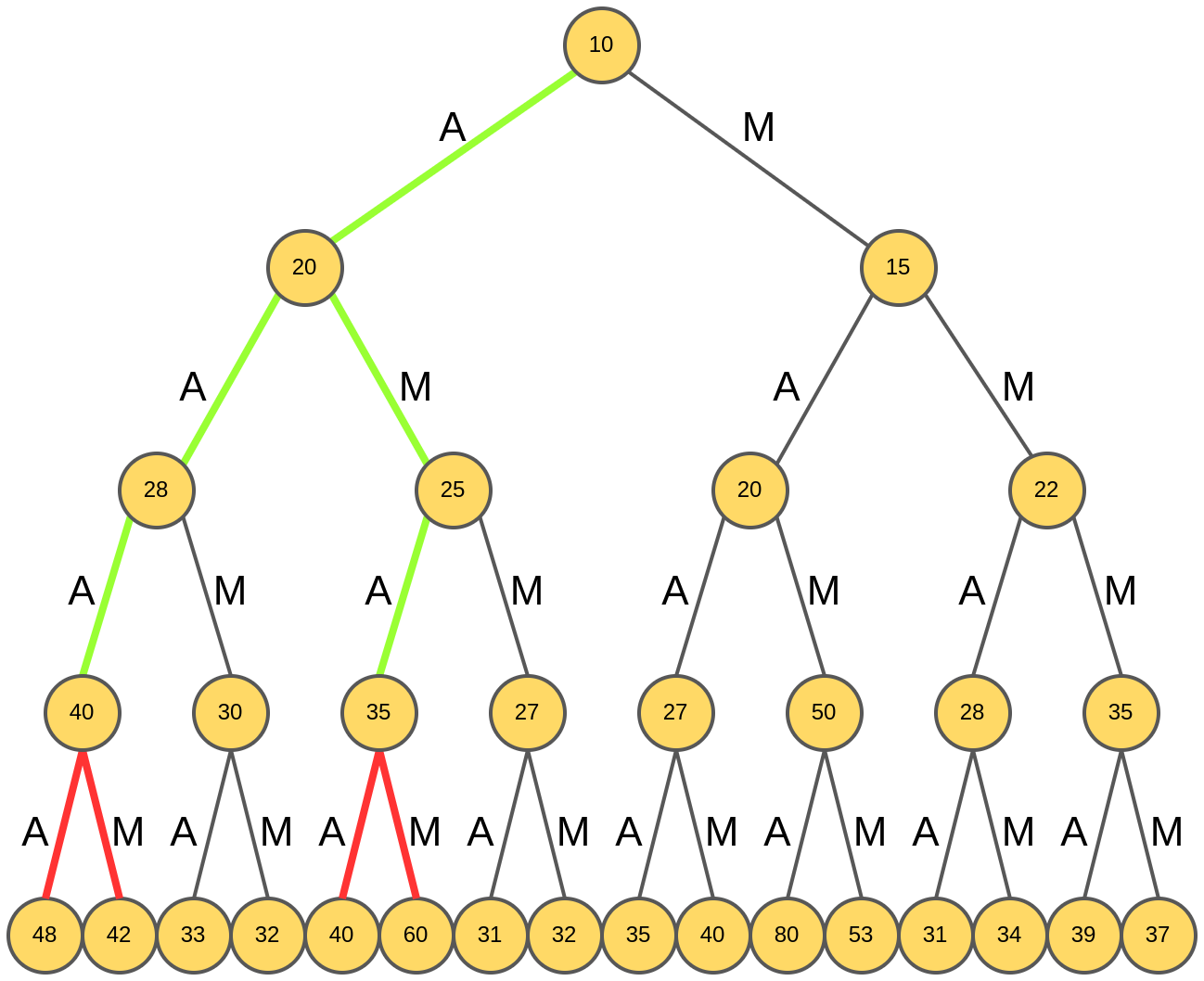
Выбираются две лучших - "AAAA" и "AMAM" с рейтингами 48 и 60:
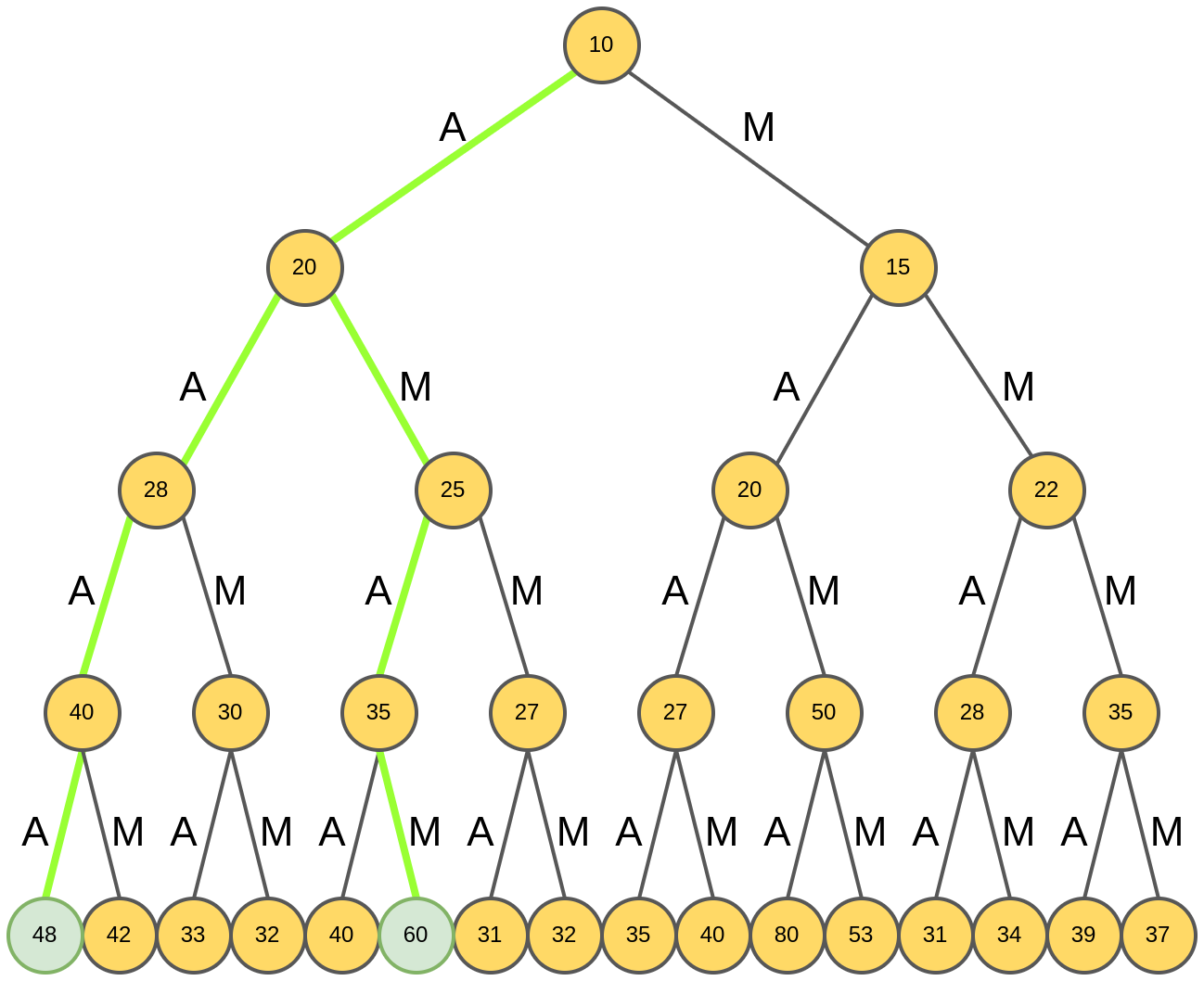
Итоговой генерацией будет слово "AMAM", обладающее максимальным рейтингом среди отобранных на предыдущем шаге.
За счёт расширения пространства поиска нам удалось сгенерировать слово с более высоким рейтингом (60), чем при использовании жадного поиска (48)!
Анализ лучевого поиска
Обратим внимание, что лучевой поиск всё же не обеспечивает полный перебор. Из-за этого мы упустили наилучшую генерацию слова "MAMA" с рейтингом 80:
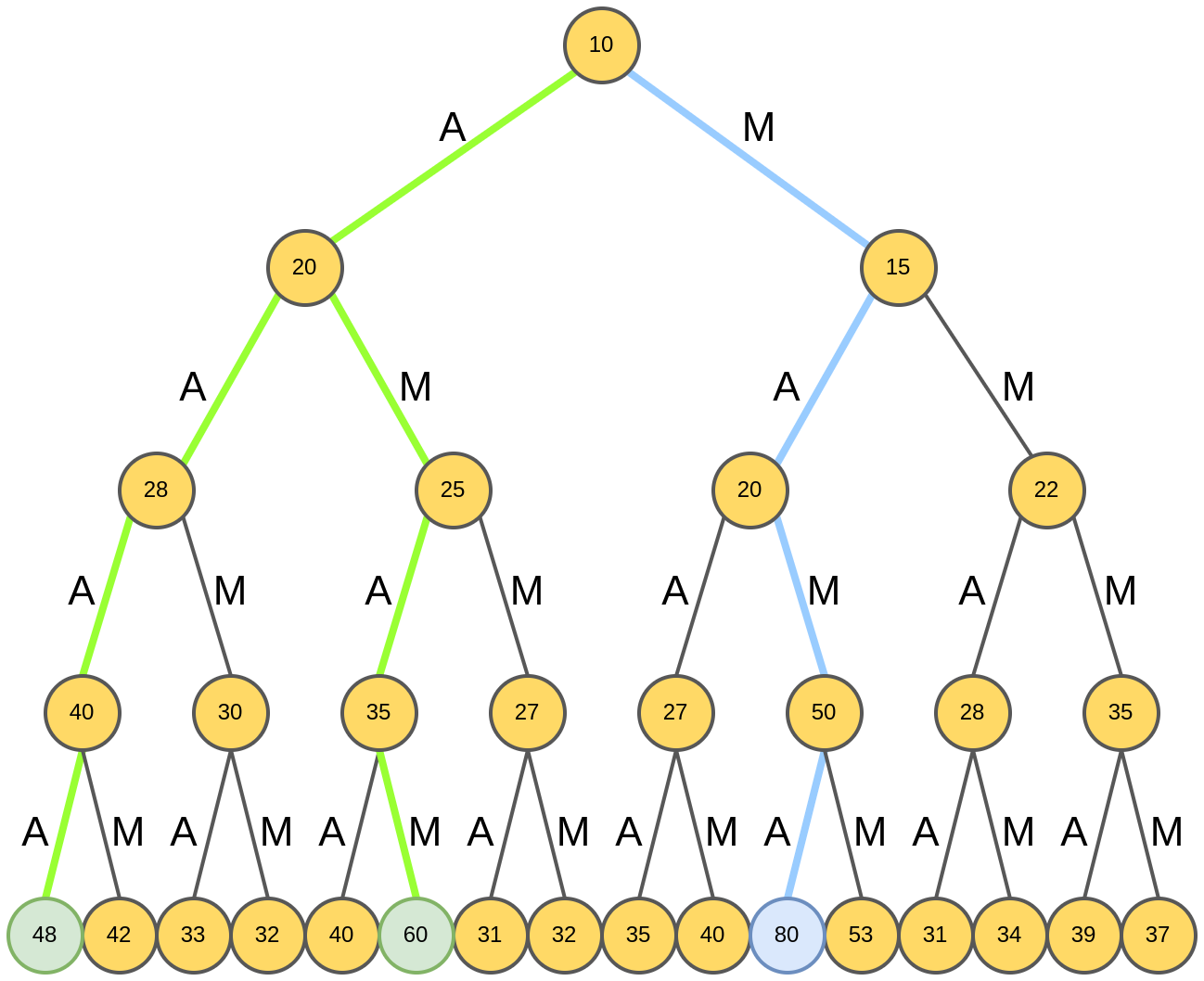
При лучевой поиск сводится к жадному алгоритму. Чем гиперпараметр выше, тем шире пространство перебора, и тем больше шансов найти не локально, а глобально оптимальное решение.
При , где - объём словаря, а - длина генерируемой последовательности, лучевой поиск сведётся к полному перебору (full search).
Дополнительно о лучевом поиске вы также можете прочитать в [1].