Генерация последовательностей
Рекуррентную сеть можно использовать для генерации последовательности , которая может представлять собой:
-
последовательность чисел (например, изменение температур);
-
последовательность вещественных векторов (например, цены на акции завтра, послезавтра, и т.д.);
-
последовательность дискретных объектов (например, цепочку слов при генерации текста).
Простая генерация (текстов, временных рядов) не имеет прикладного смысла. Гораздо большее значение имеет условная генерация (conditional generation), например, когда:
генерируется текст по заданной теме (ответ на вопрос);
генерируется временной ряд по условию (вероятная динамика будущих цен по текущей ситуации на рынке).
Поэтому безусловная генерация разрабатывается как предварительный этап перед условной генерацией в описанных далее архитектурах one-to-many и many-to-many.
Для этого в начале генерации сети подаётся некоторое фиксированное начальное состояние и фиксированный вектор начального входа .
Для безусловной генерации их можно задавать как нулевые вектора или как обучаемые константные векторы. В условной генерации эти вектора используются для кодировки условия, по которому нужно производить генерацию.
Последующая генерация несколько различается в зависимости от того, генерируем ли мы вектора вещественных чисел или дискретные объекты, такие как слова текста.
Генерация векторов чисел
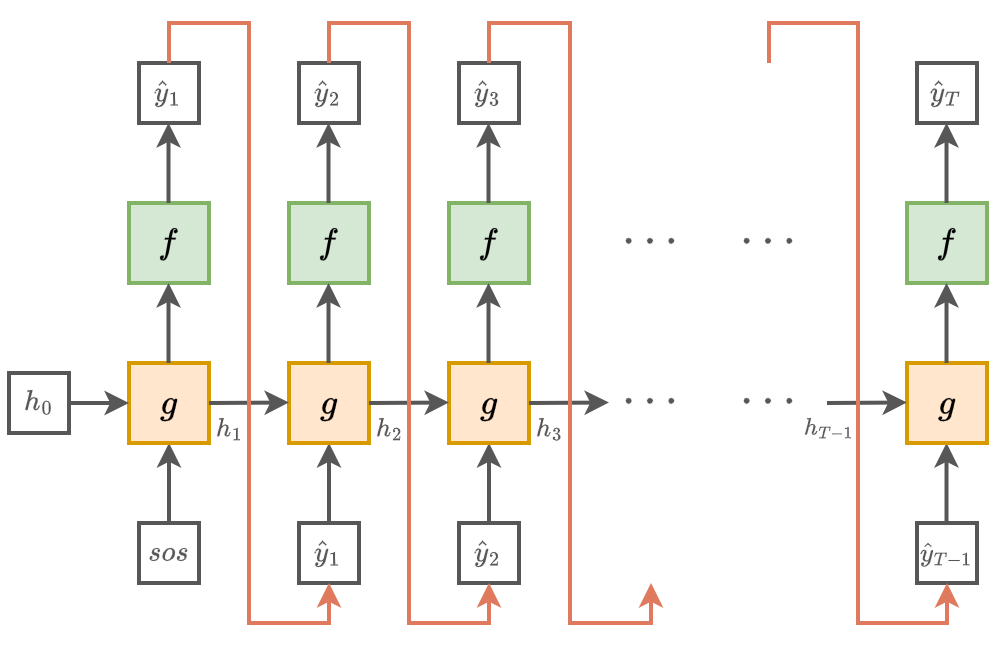
При генерации векторов вещественных чисел для рекуррентная сеть пересчитывает внутреннее состояние и выход, принимая на вход собственный выход в предыдущий момент времени. Вводится дополнительная функция , которая по внутреннему состоянию оценивает вероятность конца генерации . Как только эта вероятность становится выше некоторого пор�огового значения (например, 0.95), генерация останавливается.
Это формализуется в виде следующего алгоритма:
ЗАДАТЬ:
- (например, нулевыми векторами)
- (например, 0.95)
ПОВТОРЯТЬ:
ПОКА
ВЫХОД:
- последовательность
Графически указанный процесс генерации показан ниже:
Генерация дискретных объектов
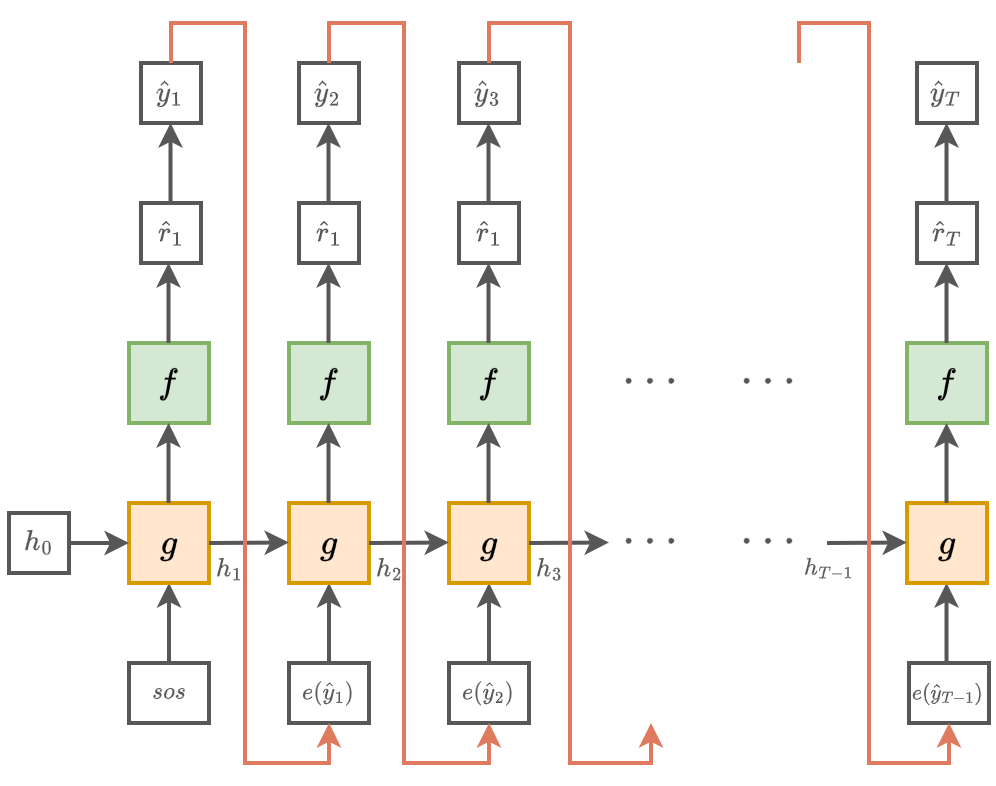
Рассмотрим, как рекуррентная сеть генерирует дискретные объекты на п�римере генерации текста (как последовательности слов).
Для слов в словаре на каждом шаге рекуррентная сеть выдаёт рейтингов каждого слова:
Эти рейтинги преобразуются в вероятности слов с помощью SoftMax-преобразования.
- Далее генерируется самое вероятное слово либо генерируемое слово сэмплируется из предсказанного распределения. Варьируя , можно управлять противоречием между согласованностью и разнообразием генерируемого текста.
На вход в следующий момент времени подаётся эмбеддинг сгенерированного слова , который можно
-
настраивать вместе с параметрами рекуррентной сети
(для больших выборок).
Графически процесс генерации будет выглядеть следующим образом:
Остановка генерации
Генерацию можно продолжать, пока предсказываемая вероятность остановки невелика (ниже порога). При генерации дискретных объектов также можно останавливать генерацию, когда будет сгенерирован специальный токен [EOS], означающий конец последовательности (end of sequence).
Обучение генеративной сети
Генеративная сеть обучается на фрагментах реальных последовательностей , где целевыми значениями выступают значения той же последовательности, сдвинутые вперёд на единицу: , чтобы сеть училась по истории последовательности предсказывать её следующий элемент.
В случае предсказания временного ряда используются регрессионные функции потерь, а в случае классификации - кросс-энтропийные между предсказанным и истинным элементом последовательности.
Free run
Если во время обучения на вход в следующий момент времени подаётся сгенерированный элемент (или его эмбеддинг для дискретных объектов), то такой режим называется free run. Он отвечает реальному применению сети, однако требует более длительного обучения, поскольку сети сложно научиться генерировать правильно всю последовательность целиком. Поэтому данный подход применяется нечасто.
Teacher forcing
Сеть будет обучаться существенно проще и быстрее, если ей упростить задачу прогнозирования. А именн�о, если подавать ей на вход реальные элементы последовательности (их эмбеддинги в дискретном случае) с предыдущего шага, а не те, которые она спрогнозировала. Так задача правильной генерации всей последовательности упрощается до правильного прогнозирования только лишь следующего элемента. Такой режим обучения называется teacher forcing.
Именно этот подход чаще всего применяется на практике во время обучения генеративных рекуррентных сетей.
Однако в режиме применения сети всё равно придётся генерировать новые последовательности на основе сгенерированных предыдущих. Если она на каком-то шаге сгенерирует неправильный вариант, то ей сложнее будет восстанавливаться и вернуться к правильной траектории генерации, поскольку сеть обучалась только на правильных входах (exposure bias)!
Объединение двух стратегий
Оптимальным с точки зрения скорости обучения и эффективности применения является комбинация двух стратегий одним из способов ниже.
Способ 1:
-
Обучить в режиме teacher forcing.
-
Дообучить в режиме free run.
Способ 2:
-
Обучать одновременно в двух режимах, когда на каждом шаге с вероятностью подаётся реальный вход, а с вероятностью - сгенерированный.
-
По ходу обучения можно постепенно уменьшать до нуля, что будет означать постепенный переход от teacher forcing к free run.
Второй способ называется Scheduled Sampling и был предложен в работе [1].
Далее мы изучим, как оценивать качество работы языковых моделей, а также как их применять, чтобы сгенерированные последовательности слов оказывались более естественными, используя лучевой поиск (beam search).