Локальное объяснение интерпретируемой моделью
Алгоритм LIME
Метод LIME (local interpretable model-agnostic explanations [1]) позволяет объяснить прогноз сложной модели для интересуемого объекта за счёт аппроксимации прогнозов этой модели другой простой и интерпретируемой моделью в окрестности точки .
Например, в задаче кредитного скоринга нас может интересовать, почему для определённого клиента кредит не был одобрен. Пусть прогноз возврата кредита осуществляется многослойной нейросетью или сложным ансамблем моделей, поэтому напрямую неинтерпретируем. Но мы можем сгенерировать много синтетических клиентов, похожих на интересующего, посмотреть на прогнозы сложной модели для этих похожих клиентов и настроить простую интерпретируемую модель, аппрок�симирующую прогнозы сложной модели в окрестности интересуемого клиента. Простыми и интерпретируемыми моделями могут выступать решающее дерево, линейная модель, метод ближайших центроидов и т.д.
Простая модель поддаётся непосредственной интерпретации, поэтому можно напрямую изучить логику её работы, чтобы делать выводы о работе сложной модели в окрестности интересующего объекта.
Метод LIME работает следующим образом:
-
Выбрать объект , для которого нужно объяснить прогноз сложной модели .
-
Сгенерировать выборку, состоящую из локальных вариаций объекта .
-
Построить для вариаций прогнозы сложной моделью , получив выборку:
-
Взвесить объекты по близости к (чем вариация ближе, тем её вес больше):
-
Настроить интерпретируемую модель по взвешенной выборке (чем вес выше, тем объект учитывается сильнее).
-
Исследовать интерпретируемую модель, аппроксимирующую прогноз сложной модели для точки .
Этапы работы алгоритма визуализированы ниже на графиках A,B,C,D [2]:
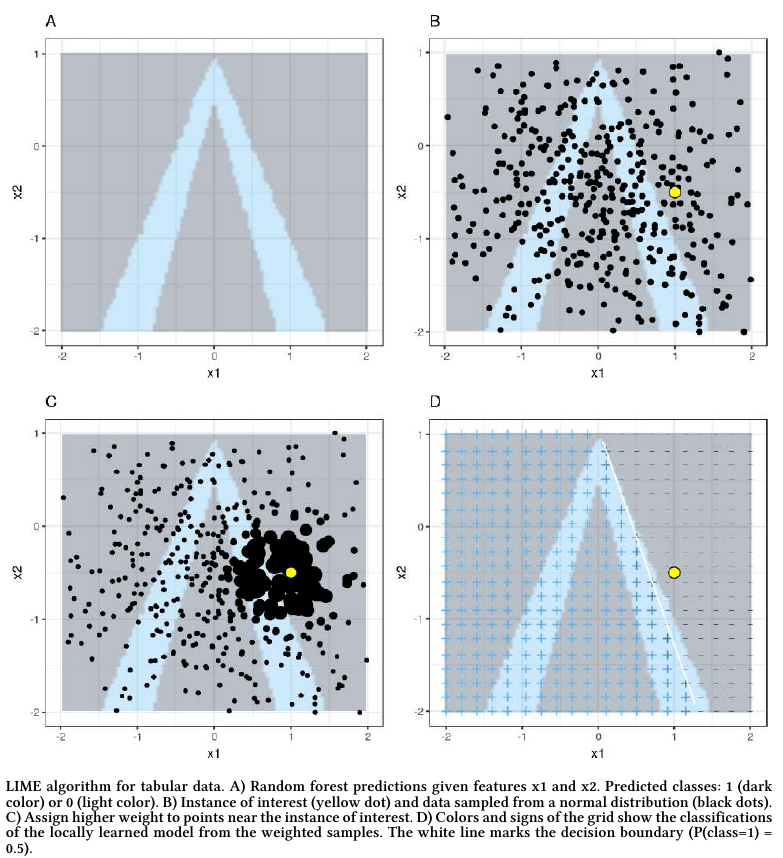
Процесс сэмплирования объектов, похожих на заданный, зависит от характера объектов:
-
Для вектора вещественных чисел можно добавлять шум с небольшой дисперсией.
-
Для текста можно включать/исключать отдельные слова.
-
Для изображения - включать/исключать отдельные суперпиксели (области соседних пикселей, примерно похожих по цвету [3]).
В качестве простой интерпретируемой модели, аппроксимирующей сложную, обычно используется:
-
Решающее дерево небольшой глубины.
-
Линейная модель с сильной L1-регуляризацией.
L1-регуляризация используется для сокращения числа признаков. Альтернативно для этого можно использовать OMP-регрессию или другой метод отбора признаков, такой как forward-selection (последовательный выбор самых важных признаков) или backward-selection (п�оследовательное исключение самых незначимых).
Контроль ошибки аппроксимации
Cтоит помнить, что простая интерпретируемая модель является лишь аппроксимацией сложной модели, поэтому важно контролировать качество её аппроксимации. Например, для задачи регрессии это может быть ошибка аппроксимации относительно ошибки аппроксимации константой:
Если ошибка аппроксимации высока, нужно либо усложнять аппроксимирующую модель (увеличивая глубину дерева или увеличивая число признаков, ослабляя L1-регуляризацию), либо уменьшить окрестность сэмплируемых вокруг интересующего объекта точек (которую при прочих равных лучше брать побольше, чтобы описать поведение исходной модели в более широкой области).
Примеры использования
Классификация текста
В [1] представлена интерпретация бинарного классификатора документа из подмножества документов датасета 20-news-groups [4], относящихся к классам christianity и atheism:
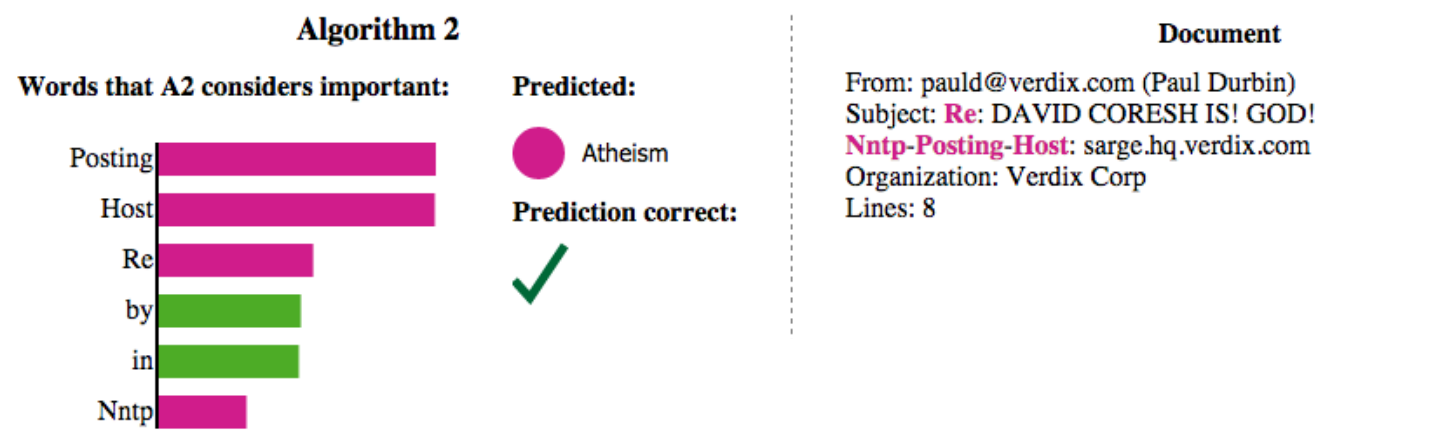
Самые значимые слова показаны слева, а начало документа - справа. Хотя классификация корректна, модель использовала нерелевантные слова Posting, Host и Re, не имеющие никакого отношения к темам христианства и атеизма! Подобный анализ позволяет выявить переобученные модели, даже если они показывают хорошее качество прогнозов.
Классификация изображений
Метод LIME можно использовать и для интерпретации моделей, классифицирующих изображения по объектам, которые на них показаны. Для этого можно сложную модель, такую как Google inception network, аппроксимировать линейным классификатором, использующим небольшое число суперпикселей. Пример по�добной интерпретации для наиболее вероятных классов приведён ниже [1]:
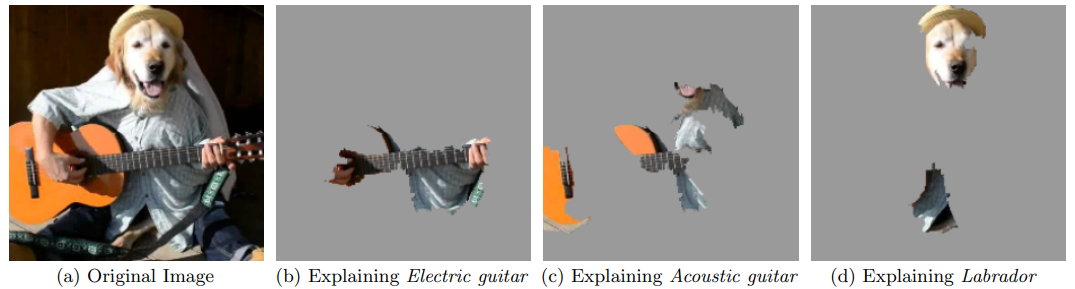
Как видим, наиболее сильно влияющие суперпиксели согласуются с классами, и модель не переобучилась.
Метод LIME на python реализован в одноимённой библиотеке. Детальнее о методе можно почитать в [2], а также в оригинальной статье [1].