Модель YOLO
Модель YOLO (You Only Look Once, [1]) - одна из простейших и самых быстрых нейросетевых моделей для задачи детекции объектов. Её архитектура представлена ниже [2]:
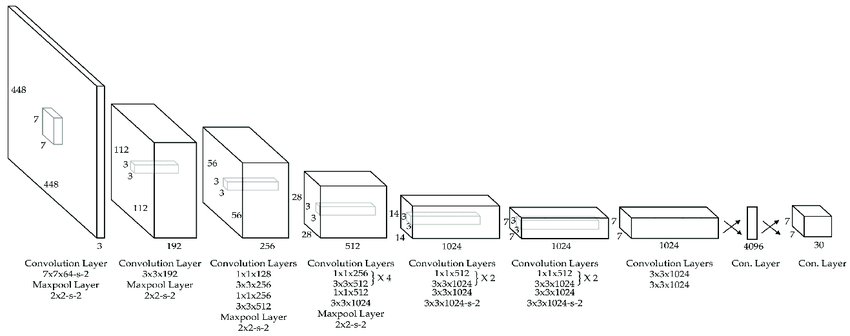
Признаки из изображения извлекаются последовательными свёрточными слоями. Для уменьшения пространственного разрешения используется шаг свёртки (stride), равный 2. Все пространственные свёртки, кроме первой, имеют размер 3x3, как в VGG. Для уменьшения числа вычислений перед применением этих свёрток число каналов уменьшается вдвое свёртками 1x1.
На первом слое, пока изображение представляет собой тензор со всего тремя каналами, применяется свёртка 7x7 и шагом 2, чтобы сразу его уменьшить и последующие вычисления вести более эффективно в уменьшенном разрешении. В конце идут два полносвязных слоя, чтобы итоговые детекции могли учитывать контекст со всего изображения.
Выход 2-го полносвязного слоя преобразуется снова в пространственный тензор размера , где
-
- размер сетки (в статье );
-
- число предсказываемых рамок объектов в каждой ячейке сетки (в статье );
-
- число классов для извлекаемых объектов.
Выходной тензор YOLO (для и ) показан ниже:
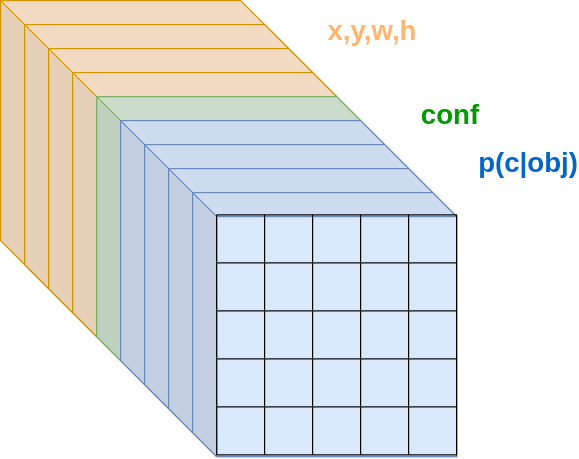
В каждой ячейке сетки предсказывается степень присутствия объекта в соответствующей ячейке, вероятностей для каждого класса при условии присутствия объекта , а также координаты левого верхнего угла рамки, выделяющей объект , и её ширина и высота .
Степень присутствия объекта вычисляется как произведение вероятности присутствия объекта (среди одного из распознаваемых классов), умноженную на степень согласованности между предсказанным и реальным выделением по мере IoU:
Когда модель обучена,
-
по величинам мы можем понять, где именно объект присутствует;
-
по условным вероятностям классов понять, какого он класса;
-
а по предсказанным - локализовать его.
Для повышения полноты поиска (recall) объект в каждой ячейке сетки локализовывался раз различными выделяющими рамками (но одним и тем же классом).
Технически на последнем слое для применялась сигмоидная функция активации (чтобы обеспечить неотрицательность), а к условным вероятностям классов применялось SoftMax-преобразование.
вычислялись как доли ширины и высоты всего изображения, а - как поправочные сдвиги относительно центра ячейки сетки, в которой детектировался объект. пропускались через нелинейность tangh.
Настройка модели
Для настройки модели YOLO в функции потерь нужно сопоставить корректные выделения объектов с выходами сети. Объект сопоставлялся той ячейке сетки , в которую попадал центр его реального выделения. Только от этой ячейки требовалось корректно предсказать наличие объекта и его выделить. Поскольку каждая ячейка делала предсказаний расположения и степени присутствия объекта, реальное выделение объекта сопоставлялось только одной лучшей попытке его выделить, у которой оказывалось максимальное IoU между предсказанной и реальной рамкой.
Итоговые потери, по которым настраивалась модель, состояли из трёх компонент:
-
точность определения, что объект присутствует;
-
точность определения класса объекта;
-
точность локализации объекта.
Точность определения, что объект присутствует
Точность обнаружения объекта вычислялась как , если объект есть, и как , если объекта нет.
Среди предсказаний присутствия объекта в каждой ячейке сетки объект считался присутствующим только для одного предсказания, обладающего максимальным IoU с истинным выделением.
Это заставляло различные предикторы расположений для одной ячейки специализироваться на своих масштабах и соотношениях сторон при локализации объектов.
Если объекта не было, то это учитывалось в функции потерь с меньшим весом, чем ситуация, когда объект был. Это было сделано, поскольку ситуаций отсутствия объекта гораздо больше, чем ситуаций, что он присутствует. Но именно последний случай представляет основной интерес.
Точность определения класса объекта
Неточности в определении того, какому классу принадлежит объект, вычисляются по квадрату -нормы расхождений вектора истинных вероятностей и предсказанных.
В последующих версиях YOLO классификационные потери считались уже по кросс-энтропийной функции потерь.
Точность локализации объекта
Неточность локализации объекта штрафуется как
Для штрафуются отклонения не самих величин, а корней из них, чтобы повысить внимание модели к точности локализации малых объектов, имеющих небольшую ширину и высоту.
Анализ модели
Архитектура YOLO проста в реализации и работает быстро. Недостатками YOLO являются:
-
невысокая точность локализации, связанная с тем, что определение координат происходит только на основе карт признаков, полученных с последнего свёрточного слоя, имеющего низкое пространственное разрешение;
-
в архитектуру конструктивно заложено ограничение на максимальное число детекций: модель не может найти на изображении больше объектов, чем использованное число ячеек выходной сетки (7x7=49 в стандартной конфигурации).
Существуют и более поздние версии YOLO (YOLO v2-v8), в которых эти недостатки во многом устранены.
Литература
- Redmon J. You only look once: Unified, real-time object detection //Proceedings of the IEEE conference on computer vision and pattern recognition. – 2016.
- Koylu C., Zhao C., Shao W. Deep neural networks and kernel density estimation for detecting human activity patterns from geo-tagged images: A case study of birdwatching on flickr //ISPRS international journal of geo-information. – 2019. – Т. 8. – №. 1. – С. 45.