Подавление немаксимумов
Базовый алгоритм NMS
Алгоритмы детекции объектов генерируют избыточное количество выделений объектов интересующих классов, как показано на рисунке справа-вверху [1]:
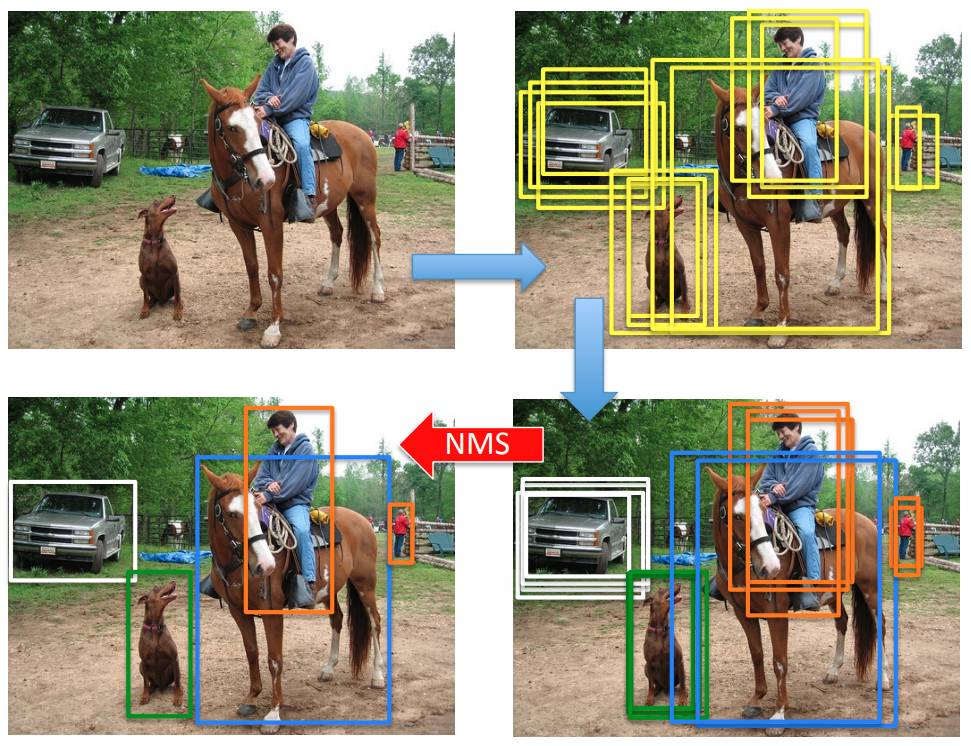
Эти выделения соотносятся тому или иному классу классификатором, назначающим степень принадлежности рамки каждому классу (рейтинг класса). Расположение самого выделения немного уточняется регрессором, как показано справа внизу.
Чтобы отобрать минимально достаточный набор выделений, используется алгоритм подавления немаксимумов (non-maximum supression, NMS), фильтрующий избыточные детекции, имеющие сильное пересечение по мере IoU с другими, обладающими более высоким рейтингом. Он применяется для каждого класса в отдельности.
Алгоритм принимает на вход набор детекций (выделяющих рамок) и соответствующих рейтингов (вероятностей определённого класса) , а на выходе выдаёт самые явные детекции без повторений с соответствующими рейтингами . Он работает следующим образом:
ВХОД:
- первоначальные детекции
- их рейтинги
- гиперпараметр NMS
АЛГОРИТМ:
- инициализируем выходные детекции
- инициализируем выходные рейтинги
пока :
для :
если , то
вернуть
где прибавление/вычитание элемента из набора означает добавление/исключение этого элемента из множества.
Мягкий вариант алгоритма NMS
Базовый алгоритм подавлени�я немаксимумов жёстко отбрасывает выделения, имеющие IoU с другим выделением, имеющим более высокий рейтинг. Это может негативно сказаться на количестве обнаруженных объектов (recall), которые сильно пересекаются, как на рисунке ниже:

Для того, чтобы этого не происходило, в работе [1] предлагается оставлять все детекции, но для выделений, имеющих сильное пересечение с другими высокорейтинговыми выделениями, дополнительно снижать рейтинг. Итоговыми детекциями будут те, у которых рейтинг выше некоторого порога , устанавливая который достаточно низким, можно извлечь большее число объектов (ценой более частых дублированных выделений одного и того же объекта).
Этот алгоритм называется мягким подавлением немаксимумов (soft-NMS) и работает следующим образом:
ВХОД:
- первоначальные детекции
- их рейтинги
- гиперпараметр NMS
АЛГОРИТМ:
- инициализируем выходные детекции
пока :
для :
вернуть
Как видим, в качестве в этот раз перебираются все детекции из , в результате чего , т.е. выходные детекции совпадают со всеми входными, однако рейтинг детекций, имеющих сильное пересечение с другими высокорейтинговыми выделениями, оказывается сниженным за счёт домножения исходного рейтинга на для некоторой убывающей функции , принимающей значения на отрезке . Предлагаются два варианта этой функции:
- линейное перевзвешивание:
-
Гауссово перевзвешивание:
Линейное �перевзвешивание приводит к разрывному масштабированию, в отличие от Гауссова. В экспериментах [1] мягкое подавление немаксимумов оказалось лучше, чем жёсткое. При этом иногда доминировало линейное, а иногда - Гауссово перевзвешивание.